Ardilla cliente como colmena con el controlador JDBC
SQuirreL SQL es una herramienta de código abierto que actúa como cliente de la colmena. Si deseas descargar este cliente SQL universal a partir de la página web de SourceForge. Proporciona una interfaz de usuario para la colmena y simplifica las tareas de consulta de tablas grandes y analizar datos con Apache Hive.
La figura ilustra cómo funcionaría la arquitectura Hive al utilizar herramientas como la ardilla.
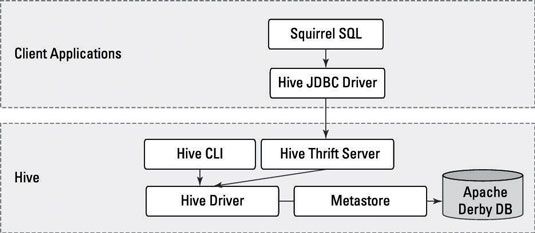
Se puede ver que el cliente SQuirreL utiliza las API de JDBC para pasar comandos al controlador de la colmena a través del servidor.
Siga estos pasos para obtener Ardilla que se ejecuta:
Inicie el Hive Thrift Server utilizando el lsiting comando:
$ $ HIVE_HOME / bin / colmena --service hiveserver -p 10000 -vStarting Hive Thrift ServerStarting Hive Thrift Server en el puerto 10000 con 100 hilos min trabajadores y subprocesos de trabajo 2147483647 max
Descargar la última distribución SQuirreL desde el sitio SourceForge en un directorio de su elección.
Descomprimir el paquete SQuirreL con el comando gunzip y expandir el archivo utilizando el comando tar.
gunzip ardilla-sql-3.5.0-standard.tar.gz- tar xvf ardilla-sql-3.5.0-standard.tar.gz
Cambie al nuevo directorio lanzamiento ardilla y iniciar la herramienta con el siguiente comando.
$ Cd ardilla-sql-3.5.0-estándar -. / Squirrel-sql.sh
Tenga en cuenta que las instrucciones para incluir el núcleo Hadoop .tarro archivo puede variar según el comunicado de Hadoop. En este caso, el Hadoop .tarro archivo fue nombrado hadoop-core-1.2.1.jar, lo que incluye $ HADOOP_HOME / hadoop - * - core.jar según las instrucciones online fue incorrecta.
Esto es todo lo que se necesita para empezar a usar la interfaz gráfica de usuario de ardilla. La siguiente figura muestra algunos HiveQL comandos corriendo contra el conductor Colmena - similar a los comandos que se ejecutó antes, con la CLI.
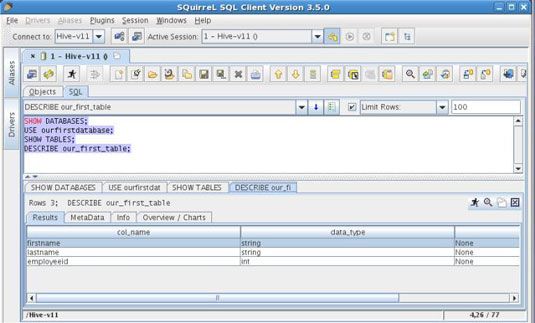
La versión de Apache Hive 0.11 también incluye un nuevo servidor Hive Thrift llamada HiveServer2. Cuando se configura correctamente, HiveServer2 puede soportar múltiples clientes (un cliente CLI y un cliente Ardilla en el mismo tiempo, por ejemplo) y proporciona mayor seguridad.



No hay mejor manera de ver lo que es lo que al instalar el software de la colmena y darle una prueba de funcionamiento. Al igual que con otras tecnologías en el ecosistema Hadoop, no se necesita mucho tiempo para empezar.Si usted tiene el tiempo y…
Aquí, se importa la totalidad de la base de datos de la orden de servicio directamente desde MySQL en la colmena y ejecuta una consulta HiveQL en contra de la base de datos recién importados de Hadoop. La siguiente lista muestra cómo se…
Usted probablemente ya sabe que los expertos en el modelado de bases de datos relacionales y diseño normalmente pasan mucho de su tiempo a diseñar bases de datos normalizados, o esquemas. Base de datos normalización es una técnica que protege…
La comunidad Apache Hive vibrante y activa continuamente añadirs a una ya extensa conjunto de características, lo que hace que la cobertura exhaustiva aún más difícil. La siguiente lista resume algunas de las características clave HiveQL para…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
En 2010, EMC y VMware, los líderes del mercado en la entrega de TI como un servicio a través de la computación en nube, adquirieron Greenplum Corporation, las personas que habían llevado con éxito el producto Greenplum MPP Data Warehouse (DW)…
Apache Hive es indiscutiblemente la interfaz de consulta de datos más extendida en la comunidad Hadoop. Originalmente, los objetivos de diseño de la colmena no eran para la compatibilidad de SQL completa y de alto rendimiento, pero eran para…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Al examinar los elementos de Apache Hive muestran, se puede ver en la parte inferior que la colmena se sienta encima del Sistema Hadoop Distributed File (HDFS) y sistemas de MapReduce.En el caso de MapReduce, los figureshows tanto los componentes 1…
HBase está escrito en Java, un lenguaje elegante para la construcción de tecnologías distribuidas como HBase, pero la cara él - no todo el mundo que quiera aprovechar las innovaciones HBase es un desarrollador Java. Es por eso que hay un rico…
Hive es una capa de datos de depósito orientado a lotes construido sobre los elementos básicos de Hadoop (HDFS y MapReduce) y es muy útil en grandes volúmenes de datos. Proporciona a los usuarios que saben de SQL con una implementación…