Cómo utilizar MapReduce para grandes datos
MapReduce es un marco de software que es ideal para grandes volúmenes de datos, ya que permite a los desarrolladores escribir programas que pueden procesar grandes cantidades de datos no estructurados en paralelo a través de un grupo distribuido de procesadores.
Conteúdo
La función de mapa de datos grande
los mapa la función ha sido parte de muchos lenguajes de programación funcionales durante años. Mapa se ha revitalizado como una tecnología básica para las listas de procesamiento de elementos de datos.
Los operadores en los lenguajes funcionales no modifican la estructura de la de datos que crean nuevas estructuras de datos como su producción. El sí de datos original es modificado también. Así que usted puede utilizar la función de mapa con la impunidad, ya que no le hará daño a sus datos almacenados preciosos.
Otra ventaja de la programación funcional es no tener que gestionar expresamente el movimiento o el flujo de los datos. Esto absuelve al programador de la gestión de forma explícita la salida de datos y colocación. Por último, el orden de las operaciones sobre los datos no se prescribe.
Una forma de lograr la solución es identificar los datos de entrada y crear una lista:
milista = ("todos los condados en los EE.UU. que participaron en la elección general más reciente")Cree la función Cuántas personas utilizando la función de mapa. Esto selecciona sólo los condados con más de 50.000 personas:
mapa howManyPeople (MYLIST) = [howManyPeople "condado 1" - howManyPeople "condado 2" - howManyPeople "condado 3" - howManyPeople "condado 4" -. . . ]
Ahora producir una nueva lista de salida de todos los condados con poblaciones superiores a 50.000:
(no, condado 1- sí, condado 2- no, condado 3- sí, condado 4-?, nnn condado)
La función se ejecuta sin realizar ningún cambio en la lista original. Además, se puede ver que cada elemento de la lista de salida se asigna a un elemento correspondiente de la lista de entrada, con un sí o no adjunta. Si el condado ha cumplido con el requisito de más de 50.000 personas, la función de mapa identifica con un sí. Si no, una no Está indicado.
Añadir la función de reducir para grandes datos
Al igual que la función de mapa, reducir ha sido una característica de los lenguajes de programación funcionales durante muchos años. La función de reducir toma la salida de una función de mapa y " reduce " la lista de cualquier manera el programador desea.
El primer paso que la función de reducir requiere es colocar un valor en algo llamado acumulador, que posee un valor inicial. Después de almacenar un valor de partida en el acumulador, al reducir la función procesa cada elemento de la lista y realiza la operación que necesita a través de la lista.
Al final de la lista, la función de reducir devuelve un valor basado en lo que la operación que quería llevar a cabo en la lista de salida.
Supongamos que es necesario identificar los condados donde la mayoría de los votos fueron para el candidato demócrata. Recuerde que su Cuántas personas función de mapa miró a cada elemento de la lista de entrada y creó una lista de salida de los condados con más de 50.000 personas (sí) Y los condados con menos de 50.000 personas (no).
Después de invocar el Cuántas personas función de mapa, que se quedan con la lista de salida siguiente:
(no, condado 1- sí, condado 2- no, condado 3- sí, condado 4-?, nnn condado)
Esta es ahora la entrada para la función de reducir. Esto es lo que parece:
countylist = (no, condado 1- sí, condado 2- no, condado 3- sí, condado 4-?, nnn condado) reducir isDemocrat (countylist)
El reducir los procesos de la función de cada elemento de la lista y devuelve una lista de todos los condados con una población superior a 50.000 habitantes, donde la mayoría votó demócrata.
Poner el gran mapa de datos y reducir juntos
A veces la producción de una lista de salida es suficiente. Del mismo modo, a veces llevar a cabo operaciones en cada elemento de una lista es suficiente. Muy a menudo, usted quiere mirar a través de grandes cantidades de datos de entrada, seleccionar ciertos elementos de los datos, y luego calcular algo de valor de las piezas pertinentes de datos.
Usted no quiere cambiar esa lista de entrada para que pueda utilizarlo de diferentes maneras con nuevas hipótesis y nuevos datos.
Software aplicaciones de diseño desarrolladores basados en algoritmos. Un algoritmo no es más que una serie de pasos que deben darse en el servicio a un objetivo general. Puede parecer un poco como esto:
Comience con un gran número o datos o registros.
Iterar sobre los datos.
Utilice la función de mapa para extraer algo de interés y crear una lista de salida.
Organizar la lista de salida para optimizar para su posterior procesamiento.
Utilice la función de reducir al calcular un conjunto de resultados.
Producir la salida final.
Los programadores pueden implementar todo tipo de aplicaciones que utilizan este enfoque, pero los ejemplos a este punto han sido muy simple, por lo que el valor real de MapReduce pueden no ser evidentes. ¿Qué sucede cuando usted tiene datos de entrada muy grandes? ¿Se puede utilizar el mismo algoritmo de terabytes de datos? La buena noticia es que sí.
Todas las operaciones parecen independiente. Eso es porque lo son. El verdadero poder de MapReduce es la capacidad de dividir y conquistar. Tome un gran problema y romperla en trozos, más pequeñas y manejables, operar sobre cada trozo de forma independiente, y luego tire de ella todos juntos al final. Además, la función de mapa es conmutativa - en otras palabras, el orden en que se ejecuta una función no importa.
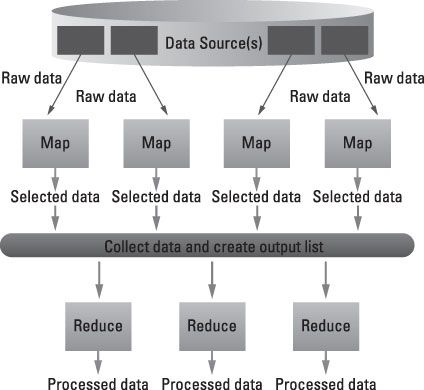
Así MapReduce puede realizar su trabajo en diferentes máquinas en una red. También se puede extraer de múltiples fuentes de datos, internos o externos. MapReduce realiza un seguimiento de su trabajo mediante la creación de una clave única para asegurar que todo el proceso está relacionado con la solución del mismo problema. Esta tecla también se usa para tirar toda la salida juntos al final de todas las tareas distribuidas.




La API de MapReduce está escrito en Java, por lo que las aplicaciones MapReduce son principalmente basados en Java. La siguiente lista especifica los componentes de una aplicación MapReduce que se puede desarrollar:Conductor (obligatorio):…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Hadoop es una plataforma de software libre de código abierto para la redacción y ejecución de aplicaciones que procesan una gran cantidad de datos para el análisis predictivo. Se permite un procesamiento paralelo distribuido de grandes conjuntos…
Una herramienta de código abierto que es únicamente útil en el análisis predictivo es Apache Mahout. Esta biblioteca de aprendizaje de máquinas incluye versiones a gran escala de la agrupación, clasificación, filtrado colaborativo y otros…
MapReduce es cada vez más útil para grandes datos. En la década de 2000, algunos ingenieros de Google miraron hacia el futuro y determinaron que mientras sus soluciones actuales para aplicaciones tales como rastreo web, frecuencia de consulta, y…
Cuando la gente habla del mapa y reducir en grandes volúmenes de datos, lo hacen con el fin de las operaciones dentro de un modelo de programación funcional. La programación funcional es una de las dos formas en que los desarrolladores de…
Su gran arquitectura de datos también tiene que actuar en concierto con infraestructura de apoyo de su organización. Por ejemplo, usted podría estar interesado en el funcionamiento de los modelos para determinar si es seguro para perforar en…
Cada función en I espera que sus datos estén en un formato específico. Eso no quiere decir simplemente si se trata de un número entero, carácter, o factor, sino también si usted proporciona un vector, una matriz, una trama de datos, o una…
los sapply () la función no siempre devuelve un vector. De hecho, la salida estándar de sapply es una lista, pero esa lista se simplifica ya sea a una matriz o un vector si es posible.Si el resultado de la función aplicada sobre cada elemento de…
R tiene un poderoso conjunto de funciones que le permite aplicar una función en varias ocasiones sobre los elementos de una lista. Lo interesante y crucial de esto es que ocurre sin un lazo explícito.Debido a que este es un concepto tan útil, te…
Una persona registra un documento registrable por llevarlo a un funcionario del condado, que tiene la obligación de mantener los registros de propiedad de bienes relativos a la propiedad en el condado. El funcionario del condado no evalúa la…