Hadoop MapReduce para grandes datos
Para entender completamente las capacidades de Hadoop MapReduce, es importante diferenciar entre Mapa reducido
Conteúdo
Es útil pensar en esta aplicación como una Mapa reducido motor, porque eso es exactamente cómo funciona. Usted proporciona entrada (combustible), el motor convierte la entrada en la salida de forma rápida y eficiente, y te dan las respuestas que necesita.
Hadoop MapReduce incluye varias etapas, cada una con un importante conjunto de operaciones que ayudan a llegar a su meta de obtener las respuestas que necesita a partir de datos grandes. El proceso comienza con una solicitud del usuario para ejecutar un programa de MapReduce y continúa hasta que los resultados se escriben de nuevo al HDFS.
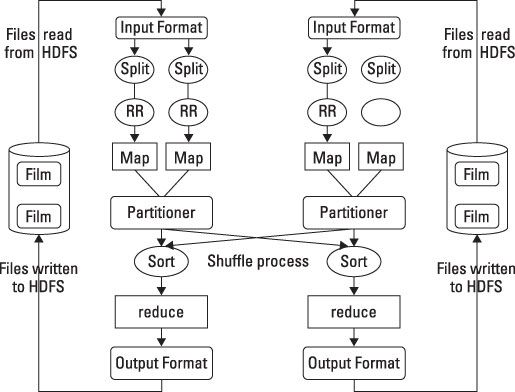
HDFS y MapReduce realizan su trabajo en los nodos de un clúster alojado en bastidores de servidores básicos. Para simplificar la discusión, el diagrama muestra sólo dos nodos.
Recibe las grandes datos listos
Cuando un cliente solicita un programa de MapReduce para funcionar, el primer paso es localizar y leer el archivo de entrada que contiene los datos en bruto. El formato de archivo es completamente arbitraria, pero los datos se debe convertir en algo que el programa puede procesar. Esta es la función de InputFormat y RecordReader. InputFormat decide cómo el archivo se va a romper en trozos más pequeños para el procesamiento usando una función llamada InputSplit.
A continuación, asigna un RecordReader para transformar los datos en bruto para su procesamiento por el mapa. Existen varios tipos de RecordReaders se suministran con Hadoop, que ofrece una amplia variedad de opciones de conversión. Esta característica es una de las formas en que Hadoop gestiona la gran variedad de tipos de datos que se encuentran en problemas de datos grandes.
Que el gran mapa de datos comienza
Tus datos se encuentra ahora en una forma aceptable para asignar. Para cada par de entrada, una instancia distinta de mapa se llama para procesar los datos. Pero, ¿qué hacer con la salida procesada, y cómo se puede hacer un seguimiento de ellos?
Mapa tiene dos capacidades adicionales para hacer frente a las preguntas. Debido mapa y reducir la necesidad de trabajar juntos para procesar sus datos, el programa necesita para recoger la salida de los cartógrafos independientes y pasarlo a los reductores. Esta tarea es realizada por un OutputCollector. Una función Reporter también ofrece la información obtenida de las tareas de mapa para que sepa cuándo o si las tareas mapa están completos.
Todo este trabajo se está realizando en varios nodos del clúster Hadoop simultáneamente. Es posible que los casos en que la salida de ciertos procesos de asignación tiene que ser acumulados antes de que comiencen los reductores. O bien, algunos de los resultados intermedios pueden necesitar ser procesada antes de la reducción.
Además, parte de esta salida puede haber en un nodo distinto del nodo en el que los reductores para que la producción específica se ejecutarán. La recogida y redistribución de los resultados intermedios se realizan por un particionador y una especie. Las tareas mapa entregarán los resultados a una partición específica como entradas a las tareas de reducir.
Después de todas las tareas de mapa se completa, los resultados intermedios se reunieron en la partición y un revolver ocurre, la clasificación de la salida para el procesamiento óptimo de reducir.
Reducir y combinar para grandes datos
Para cada par de salidas, reducen está llamado a realizar su tarea. De manera similar al mapa, reducir recoge su salida, mientras que todas las tareas están procesando. Reducir no pueden comenzar hasta que se hace todo el mapeo. La salida de reducir también es una clave y un valor. Mientras que esto es necesario para reducir el para hacer su trabajo, puede que no sea el formato de salida más eficaz para su aplicación.
Hadoop proporciona una característica OutputFormat, y funciona muy parecido a InputFormat. OutputFormat toma el par clave-valor y organiza la salida para escribir en HDFS. La última tarea es escribir realmente los datos a HDFS. Esto se realiza mediante RecordWriter, y se lleva a cabo de manera similar a RecordReader excepto en sentido inverso. Toma los datos OutputFormat y lo escribe en HDFS en la forma necesaria para los requisitos del programa.
La coordinación de todas estas actividades se gestiona en las versiones anteriores de Hadoop por un planificador de tareas. Este planificador era rudimentario, y como la mezcla de puestos de trabajo cambió y creció, estaba claro que un enfoque diferente era necesario. La deficiencia primaria en el antiguo planificador fue la falta de gestión de los recursos. La última versión de Hadoop tiene esta nueva capacidad.
Hadoop MapReduce es el corazón del sistema de Hadoop. Proporciona todas las capacidades que necesita para romper los grandes datos en partes manejables, procesar los datos en paralelo en el clúster distribuido, y luego hacer que los datos disponibles para el consumo usuario o procesamiento adicional. Y lo hace todo este trabajo de una manera altamente resistente, con tolerancia a fallos. Este es solo el comienzo.
-
 Construir una base de datos grande con el ecosistema Hadoop
Construir una base de datos grande con el ecosistema Hadoop - Cloudera impala y hadoop
- Procesamiento distribuido con MapReduce Hadoop
- Los factores que aumentan la escala de análisis estadístico en hadoop
-
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación - Cerdo Hadoop y latín de cerdo para los grandes datos
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el…
La API de MapReduce está escrito en Java, por lo que las aplicaciones MapReduce son principalmente basados en Java. La siguiente lista especifica los componentes de una aplicación MapReduce que se puede desarrollar:Conductor (obligatorio):…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.Cerdo tiene dos modos de ejecutar secuencias de comandos:Modo local: Todos…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
El componente central de hilo (Sin embargo, otro negociador de recursos) es el Administrador de recursos, que regula todos los recursos de procesamiento de datos en el cluster Hadoop. En pocas palabras, el Administrador de recursos es un programador…