Ejecución de aplicaciones antes hadoop 2
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en el papel que los demonios maestros JobTracker y demonios esclavos TaskTracker jugaron en el manejo de procesamiento MapReduce.
El punto de emplear sistemas distribuidos es ser capaz de desplegar los recursos informáticos en una red de ordenadores autónomos de una manera que es tolerante a fallos, fácil, y barato.
En un sistema distribuido, como Hadoop, donde se tiene un grupo de nodos de computación auto-contenida todos trabajando en paralelo, una gran cantidad de complejidad va en asegurar que todas las piezas funcionan juntos. Como tal, estos sistemas tienen típicamente capas distintas para manejar diferentes tareas para apoyar el procesamiento de datos en paralelo.
Este concepto, conocido como el separación de intereses, asegura que si usted es, por ejemplo, el programador de la aplicación, usted no tiene que preocuparse por los detalles específicos para, por ejemplo, la conmutación por error de tareas mapa. En Hadoop, el sistema consta de estos cuatro capas distintas, como se muestra:
Almacenamiento distribuido: El sistema de archivos distribuido Hadoop (HDFS) es la capa de almacenamiento donde se almacenan los datos, los resultados provisionales, y los conjuntos de resultados finales.
Administracion de recursos: Además de espacio en disco, todos los nodos esclavos del clúster Hadoop tienen ciclos de CPU, RAM, y ancho de banda de la red. Un sistema como Hadoop tiene que ser capaz de repartir estos recursos para que múltiples aplicaciones y los usuarios pueden compartir el cluster de forma predecible y ajustables. Este trabajo está hecho por el demonio JobTracker.
Marco de procesamiento: El flujo del proceso MapReduce define la ejecución de todas las aplicaciones en Hadoop 1. Esto comienza con el mapa de fase continua con la agregación con shuffle, el género, o merge- y termina con la fase de reducir. En Hadoop 1, esto también es administrada por el demonio JobTracker, con ejecución local siendo gestionado por demonios TaskTracker que se ejecutan en los nodos esclavos.
Application Programming Interface (API): Las aplicaciones desarrolladas para Hadoop 1 necesitaban ser codificado utilizando la API de MapReduce. En Hadoop 1, los proyectos de la colmena y cerdo proporcionan programadores con interfaces más fáciles para escribir aplicaciones de Hadoop, y debajo de la campana, su código compila hasta MapReduce.
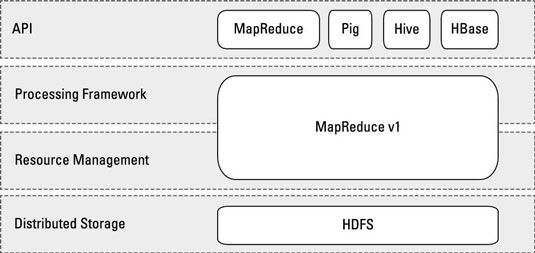
En el mundo de Hadoop 1 (que era el único mundo que tenía hasta hace muy poco), todo el procesamiento de datos girado en torno MapReduce.


 federación")
A menudo en la infancia de Hadoop, una gran cantidad de debate se centra en la representación de la NameNode de un único punto de fallo. Hadoop, en general, ha tenido siempre una arquitectura robusta y el fracaso-tolerante, con la excepción de…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.Cerdo tiene dos modos de ejecutar secuencias de comandos:Modo local: Todos…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
A diferencia de otros componentes HILO (otro negociador de recursos aún), ningún componente en Hadoop 1 asigna directamente al Maestro de aplicaciones. En esencia, este es un trabajo que el JobTracker hizo para cada aplicación, pero la…