Replicar los bloques de datos en el sistema de archivos distribuido hadoop
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para garantizar la alta disponibilidad de los datos.
Planear con anticipación para el desastre, el cerebro detrás de HDFS tomaron la decisión de configurar el sistema para que se almacenaría tres (contar 'em - tres) copias de cada bloque de datos.
HDFS asume que cada disco y cada nodo esclavo es inherentemente poco fiables, por lo que, claramente, se debe tener cuidado en la elección de la que se almacenan las tres copias de los bloques de datos.
La figura muestra cómo los bloques de datos desde el archivo anterior son rayas en el clúster Hadoop - lo que significa que se distribuyen uniformemente entre los nodos esclavos para que una copia del bloque seguirá estando disponible, independientemente de los fallos de disco, nodo, o rack.
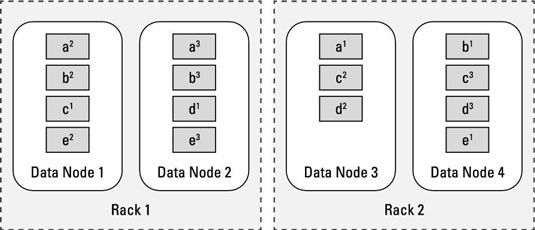
El archivo se muestra cuenta con cinco bloques de datos, etiquetados a, b, c, d, y e. Si usted echa un vistazo más de cerca, se puede ver este grupo en particular se compone de dos bastidores con dos nodos de cada uno, y que los tres ejemplares de cada bloque de datos se han extendido a través de los distintos nodos esclavos.
Cada componente del clúster Hadoop es visto como un punto de falla potencial, así que cuando HDFS almacena las réplicas de los bloques originales de todo el clúster Hadoop, trata de asegurar que las réplicas de bloques se almacenan en diferentes puntos de falla.
Por ejemplo, echar un vistazo en el Bloque A. En el tiempo que necesitaba para ser almacenados, Nodo esclavo 3 fue elegido, y la primera copia del bloque A se almacena allí. Para múltiples sistemas de estantes, HDFS determina entonces que las dos copias restantes del bloque A necesitan ser almacenados en un soporte diferente. Así que la segunda copia de bloque A se almacena en el nodo esclavo 1.
La copia final se puede almacenar en el mismo bastidor que la segunda copia, pero no en el mismo nodo esclavo, por lo que se almacena en el nodo esclavo 2.
-
 3 configuraciones de clúster Hadoop
3 configuraciones de clúster Hadoop -
 Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop
Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop -
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) -
 Procesamiento distribuido con MapReduce Hadoop
Procesamiento distribuido con MapReduce Hadoop -
 Nodos de borde en racimos de Hadoop
Nodos de borde en racimos de Hadoop - Los factores que aumentan la escala de análisis estadístico en hadoop
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
A menudo en la infancia de Hadoop, una gran cantidad de debate se centra en la representación de la NameNode de un único punto de fallo. Hadoop, en general, ha tenido siempre una arquitectura robusta y el fracaso-tolerante, con la excepción de…
Un principio básico de Hadoop está escalando con nodos esclavos adicionales para satisfacer la creciente de datos en el almacenamiento y demandas -Procesamiento. En un modelo a escala de salida, debe considerar cuidadosamente el diseño clúster…
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
Al igual que la muerte y los impuestos, fallos de disco (y dado el tiempo suficiente, incluso errores de nodo o bastidor), son inevitables en Hadoop Distributed File System (HDFS). En el ejemplo mostrado, incluso si un rack fallara, el grupo podría…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…