Errores de nodo y disco esclavo en HDFS
Al igual que la muerte y los impuestos, fallos de disco (y dado el tiempo suficiente, incluso errores de nodo o bastidor), son inevitables en Hadoop Distributed File System (HDFS). En el ejemplo mostrado, incluso si un rack fallara, el grupo podría continuar su funcionamiento. Rendimiento sufriría porque ha perdido la mitad de sus recursos de procesamiento, pero el sistema está todavía en línea y todos los datos son todavía disponibles.
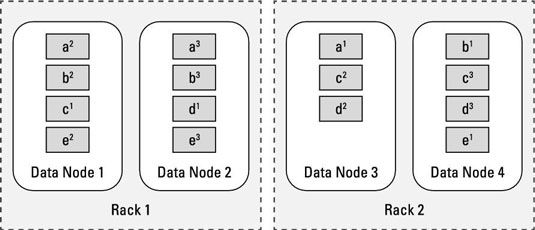
En un escenario en el que falla una unidad de disco o un nodo esclavo, el servidor de metadatos central para HDFS (llamado NameNode) finalmente encuentra que los bloques del archivo almacenados en el recurso fallado ya no están disponibles. Por ejemplo, si Slave Nodo 3 falla, esto significaría que los bloques A, C, y D son underreplicated.
En otras palabras, muy pocas copias de estos bloques están disponibles en HDFS. Cuando HDFS detecta que un bloque se underreplicated, ordena una nueva copia.
Para continuar con el ejemplo, decir que nodo Esclavo 3 viene de nuevo en línea después de unas horas. Mientras tanto, HDFS ha asegurado que hay tres copias de todos los bloques del archivo. Así que ahora, los bloques A, C, y D tienen cuatro copias cada uno y son overreplicated. Al igual que con los bloques underreplicated, el servidor de metadatos central de HDFS se enterará de esto también, y ordenará una copia de todos los archivos que desea eliminar.
Un buen resultado de la disponibilidad de los datos es que cuando se producen fallos de disco, no hay necesidad de sustituir inmediatamente los discos duros que han fallado. Esta forma más eficaz se puede hacer en intervalos regulares.
-
 3 configuraciones de clúster Hadoop
3 configuraciones de clúster Hadoop -
 Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop
Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop -
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) -
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación -
 alta disponibilidad") Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad
Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad -
 Hadoop de archivos distribuido comandos de shell del sistema
Hadoop de archivos distribuido comandos de shell del sistema
Un principio básico de Hadoop está escalando con nodos esclavos adicionales para satisfacer la creciente de datos en el almacenamiento y demandas -Procesamiento. En un modelo a escala de salida, debe considerar cuidadosamente el diseño clúster…
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…