Hadoop sistema de archivos distribuido (HDFS) para proyectos de grandes volúmenes de datos
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto único de capacidades necesarias cuando los volúmenes y la velocidad de datos son altas. Debido a que los datos se escriben una vez y luego leer muchas veces a partir de entonces, en lugar de las constantes de lectura-escritura de otros sistemas de archivos, HDFS es una excelente opción para apoyar el análisis de datos grande.
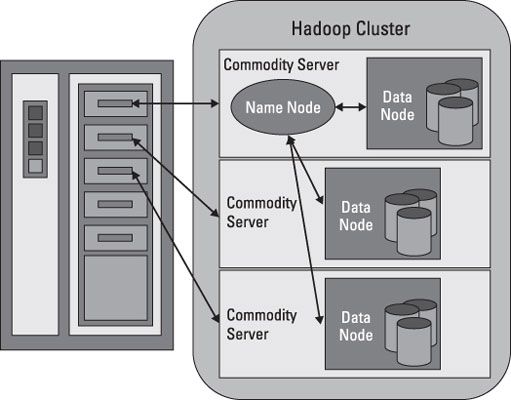
NameNodes de datos grandes
HDFS trabaja rompiendo archivos de gran tamaño en partes más pequeñas llamadas bloques. Los bloques se almacenan en los nodos de datos, y es responsabilidad del NameNode saber qué bloques en los que los nodos de datos conforman el archivo completo. El NameNode también actúa como una " policía de tráfico, " la gestión de todos los accesos a los archivos.
La colección completa de todos los archivos en el clúster se refiere a veces como el sistema de archivos espacio de nombres. Es el trabajo del NameNode para gestionar este espacio de nombres.
A pesar de que existe una fuerte relación entre el NameNode y los nodos de datos, que operan en un " débilmente acoplados " la moda. Esto permite que los elementos de racimo se comporten de forma dinámica, añadiendo servidores como la demanda aumenta. En una configuración típica, que encuentre uno NameNode y, posiblemente, un nodo de datos se ejecuta en un servidor físico en el bastidor. Otros servidores funcionan sólo nodos de datos.
Los nodos de datos se comunican entre sí de modo que puedan cooperar durante las operaciones normales del sistema de archivos. Esto es necesario porque bloques para un archivo es probable que sean almacenados en múltiples nodos de datos. Desde el NameNode es tan importante para el correcto funcionamiento de la agrupación, que puede y debe ser replicado para protegerse de un solo punto de fallo.
Nodos de datos grandes
Nodos de datos no son inteligentes, pero son resistentes. Dentro del grupo de HDFS, bloques de datos se replican a través de múltiples nodos de datos y el acceso es administrado por el NameNode. El mecanismo de replicación está diseñado para un rendimiento óptimo cuando todos los nodos del clúster se recogen en un bastidor. De hecho, el NameNode utiliza una " estante ID " hacer un seguimiento de los nodos de datos del cluster.
Nodos de datos también proporcionan " latido " mensajes para detectar y asegurar la conectividad entre el NameNode y los nodos de datos. Cuando un latido del corazón ya no está presente, la NameNode unmaps el nodo de datos del clúster y sigue funcionando como si nada hubiera pasado. Cuando el latido del corazón devuelve, se agrega al clúster de forma transparente con respecto al usuario o aplicación.
Integridad de los datos es una característica clave. HDFS apoya una serie de funciones diseñadas para proporcionar integridad de datos. Como era de esperar, cuando los archivos se dividen en bloques y luego distribuidos a través de diferentes servidores en el clúster, cualquier variación en el funcionamiento de cualquier elemento puede afectar a la integridad de datos. HDFS utiliza registros de transacciones y validación de suma de comprobación para garantizar la integridad de todo el clúster.
Los registros de transacciones seguimiento de todas las operaciones y son eficaces en la auditoría o la reconstrucción del sistema de archivos debe ocurrir algo malo.
Validaciones de suma de comprobación se utilizan para garantizar el contenido de archivos en HDFS. Cuando un cliente solicita un archivo, puede verificar el contenido mediante el examen de su suma de comprobación. Si la suma de comprobación coincide, la operación de archivo puede continuar. Si no, se informa de un error. Archivos de control están ocultos para ayudar a evitar la manipulación.
Nodos de datos utilizan discos locales en el servidor de los productos básicos para la persistencia. Todos los bloques de datos se almacenan localmente, principalmente por razones de rendimiento. Los bloques de datos se replican a través de varios nodos de datos, por lo que el fallo de un servidor no necesariamente un archivo corrupto. El grado de replicación, se estableció el número de nodos de datos y el espacio de nombres HDFS cuando se implementa la agrupación.
HDFS para grandes datos
HDFS aborda grandes desafíos de datos mediante la ruptura de los archivos en una colección relacionada de bloques más pequeños. Estos bloques se distribuyen entre los nodos de datos del cluster HDFS y son gestionados por el NameNode. Tamaños de bloque son configurables y suelen ser de 128 megabytes (MB) o 256 MB, lo que significa que un archivo de 1GB consume ocho bloques de 128MB para sus necesidades de almacenamiento básicos.
HDFS es resistente, por lo que estos bloques se replican en todo el clúster en caso de un fallo del servidor. ¿Cómo HDFS un seguimiento de todas estas piezas? La respuesta corta es el sistema de archivos metadatos.
Los metadatos se define como " datos sobre los datos ". Piense en HDFS metadatos como una plantilla para proporcionar una descripción detallada de los siguientes:
Cuando se creó el archivo, acceso, modificación, borrado, etc.
Cuando los bloques del archivo se almacenan en el cluster
¿Quién tiene los derechos para ver o modificar el archivo
¿Cuántos archivos se almacenan en el clúster
¿Cuántos datos existen nodos del clúster
La ubicación del registro de transacciones para el clúster
Metadatos HDFS se almacena en el NameNode, y mientras que el grupo está en funcionamiento, todos los metadatos se carga en la memoria física del servidor NameNode. Como era de esperar, cuanto mayor sea el grupo, más grande es la huella de metadatos.
¿Qué hace exactamente un servidor de bloque? Echa un vistazo a la siguiente lista:
Almacena los bloques de datos en el sistema de archivos local del servidor. HDFS está disponible en muchos sistemas operativos diferentes y se comporta de la misma ya sea en Windows, Mac OS o Linux.
Almacena el metadatos de un bloque en el sistema de archivos local basado en la plantilla de metadatos en el NameNode.
Realiza validaciones periódicas de las sumas de comprobación de archivos.
Envía informes periódicos a la NameNode acerca de lo que están disponibles para operaciones de archivo bloques.
Proporciona metadatos y datos a los clientes en la demanda. HDFS admite el acceso directo a los nodos de datos de programas de aplicación cliente.
Forwards datos a otros nodos de datos basados en una " canalización " modelo.
La colocación de bloques en los nodos de datos es esencial para la replicación y el apoyo a la canalización de datos de datos. HDFS mantiene una réplica de cada bloque a nivel local. HDFS es serio acerca de la replicación de datos y capacidad de recuperación.



")


La razón la gente degustar sus datos antes de ejecutar el análisis estadístico en Hadoop es que este tipo de análisis a menudo requiere importantes recursos de computación. Esto no es sólo acerca de los volúmenes de datos: hay cinco factores…
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
A menudo en la infancia de Hadoop, una gran cantidad de debate se centra en la representación de la NameNode de un único punto de fallo. Hadoop, en general, ha tenido siempre una arquitectura robusta y el fracaso-tolerante, con la excepción de…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
Al igual que la muerte y los impuestos, fallos de disco (y dado el tiempo suficiente, incluso errores de nodo o bastidor), son inevitables en Hadoop Distributed File System (HDFS). En el ejemplo mostrado, incluso si un rack fallara, el grupo podría…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…