Hadoop distribuido sistema de archivos (HDFS) federación
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos grupos fueron capaces de escalar más allá de 3.000 o 4.000 nodos.
Necesidad de NameNode para mantener registros para cada bloque de datos almacenados en el grupo resultó ser el factor más significativo restringir mayor crecimiento clúster. Cuando usted tiene demasiados bloques, se hace cada vez más difícil para el NameNode a escala como el cluster Hadoop escalas a cabo.
En concreto, debe establecer HDFS de modo que tiene varias instancias NameNode que se ejecutan en sus propios nodos maestros dedicados y luego haciendo cada NameNode responsable únicamente de los bloques de archivos en su propio espacio de nombre.
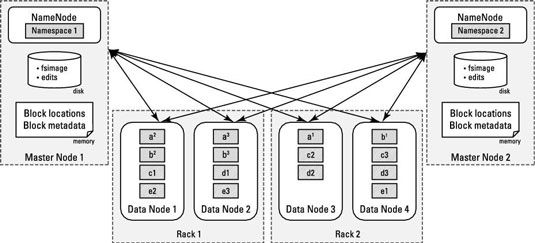
La figura muestra los patrones de replicación de bloques de datos en HDFS. Se puede ver un cluster Hadoop con dos NameNodes servir un solo clúster. Los nodos esclavos todos contienen bloques de ambos espacios de nombres.
-
 3 configuraciones de clúster Hadoop
3 configuraciones de clúster Hadoop -
 Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop
Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop -
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) -
 Procesamiento distribuido con MapReduce Hadoop
Procesamiento distribuido con MapReduce Hadoop -
 Nodos de borde en racimos de Hadoop
Nodos de borde en racimos de Hadoop - Comandos de administración de Hadoop
A menudo en la infancia de Hadoop, una gran cantidad de debate se centra en la representación de la NameNode de un único punto de fallo. Hadoop, en general, ha tenido siempre una arquitectura robusta y el fracaso-tolerante, con la excepción de…
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Como con cualquier sistema distribuido, redes puede hacer o deshacer un cluster Hadoop: No " ir barato ". Una gran parte de la charla tiene lugar entre los nodos principales y nodos esclavos en un clúster Hadoop que es esencial para mantener el…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…