Entrada divide en MapReduce de Hadoop
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos archivos.
En HILO, cuando se inicia un trabajo MapReduce, el Administrador de recursos (la gestión de recursos de clúster y la facilidad de programación de trabajos) crea un daemon maestro de aplicaciones para cuidar el ciclo de vida del trabajo. (En Hadoop 1, el JobTracker supervisa los trabajos individuales, así como el manejo de la planificación de tareas y gestión de recursos de clúster.)
Una de las primeras cosas que la Aplicación Maestro hace es determinar que se necesitan bloques de archivos para su procesamiento. La aplicación Maestro pide detalles del NameNode en donde se almacenan las réplicas de los bloques de datos necesarios. Utilizando los datos de ubicación de los bloques de archivos, la Aplicación Maestro hace peticiones al Administrador de recursos tengan tareas mapa procesar bloques específicos sobre los nodos esclavos donde están almacenados.
La clave para el procesamiento MapReduce eficiente es que, siempre que sea posible, se procesan los datos localmente - en el nodo esclavo, donde se almacena.
Antes de ver cómo se procesan los bloques de datos, es necesario mirar más de cerca cómo almacena los datos de Hadoop. En Hadoop, los archivos se componen de registros individuales, que son en última instancia procesadas uno por uno por tareas Mapper.
Por ejemplo, el conjunto de datos de muestra contiene información sobre vuelos completados dentro de los Estados Unidos entre 1987 y 2008.
Para descargar el conjunto de datos de muestra, abra el navegador Firefox desde dentro de la máquina virtual, e ir a la página de dataexpo.
Usted tiene un archivo grande para cada año, y dentro de cada archivo, cada línea individual representa un solo vuelo. En otras palabras, una línea representa un registro. Ahora, recuerde que el tamaño de bloque para el clúster Hadoop es de 64 MB, lo que significa que los archivos de datos de luz se rompen en pedazos de exactamente 64 MB.
¿Ves el problema? Si cada tarea mapa procesa todos los registros en un bloque de datos específico, ¿qué sucede con aquellos registros que abarcan límites de los bloques? Bloques de archivos son exactamente 64 MB (o lo que se establece el tamaño de bloque a ser), y porque HDFS no tiene idea de lo que hay dentro de los bloques de archivos, no se pueden medir cuando un registro podría extenderse a otro bloque.
Para resolver este problema, Hadoop utiliza una representación lógica de los datos almacenados en bloques de archivo, conocidos como divisiones de entrada. Cuando un cliente de trabajo MapReduce calcula las divisiones de entrada, que se da cuenta de que el primer disco entero en un bloque comienza y donde termina el último registro en el bloque.
En los casos en que el último registro en un bloque es incompleta, la división de entrada incluye información de ubicación para el siguiente bloque y el desplazamiento de los datos necesarios para completar el registro de bytes.
La figura muestra esta relación entre los bloques de datos y escisiones de entrada.
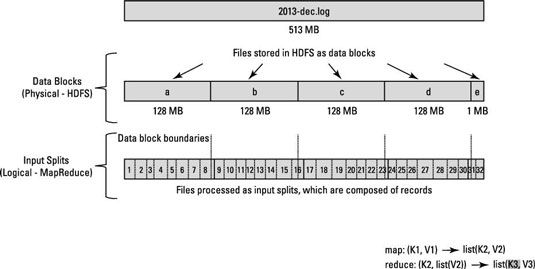
Puede configurar el daemon maestro de aplicaciones (o JobTracker, si estás en Hadoop 1) para calcular la entrada se divide en lugar del cliente de trabajo, lo que sería más rápido para los puestos de trabajo de procesamiento de un gran número de bloques de datos.
Procesamiento de datos MapReduce es impulsado por este concepto de divisiones de entrada. El número de divisiones de entrada que se calcula para una aplicación específica determina el número de tareas Mapper. Cada una de estas tareas asignador se asigna, cuando sea posible, a un nodo esclavo donde se almacena la división de entrada. El Administrador de recursos (o JobTracker, si estás en Hadoop 1) hace todo lo posible para garantizar que la entrada divisiones se procesan localmente.
-
 Datos de compresión en hadoop
Datos de compresión en hadoop -
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) - Procesamiento distribuido con MapReduce Hadoop
-
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación -
 alta disponibilidad") Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad
Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad -
 para proyectos de grandes volúmenes de datos") Hadoop sistema de archivos distribuido (HDFS) para proyectos de grandes volúmenes de datos
Hadoop sistema de archivos distribuido (HDFS) para proyectos de grandes volúmenes de datos
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el…
Para mostrar cómo los distintos HILO (otro negociador de recursos) los componentes trabajan juntos, se puede caminar a través de la ejecución de una aplicación. Por el bien del argumento, que puede ser una aplicación de MapReduce, con la…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
Al igual que la muerte y los impuestos, fallos de disco (y dado el tiempo suficiente, incluso errores de nodo o bastidor), son inevitables en Hadoop Distributed File System (HDFS). En el ejemplo mostrado, incluso si un rack fallara, el grupo podría…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
A diferencia de otros componentes HILO (otro negociador de recursos aún), ningún componente en Hadoop 1 asigna directamente al Maestro de aplicaciones. En esencia, este es un trabajo que el JobTracker hizo para cada aplicación, pero la…