¿Cómo poner en marcha una aplicación de MapReduce en hadoop 1
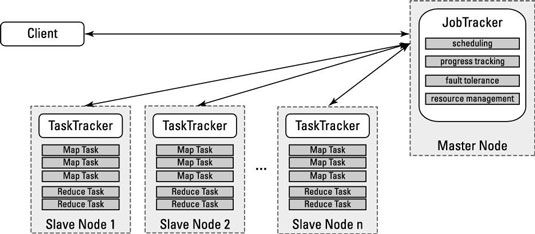
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el play-by-play:
La aplicación cliente envía una solicitud de aplicación a la JobTracker.
El JobTracker determina cómo se necesitan muchos recursos de procesamiento para ejecutar toda la aplicación.
Esto se hace mediante la solicitud de los lugares y los nombres de los archivos y bloques de datos que la aplicación necesita de la NameNode, y el cálculo de cuántas tareas mapa y reducir las tareas serán necesarios para procesar todos estos datos.
El JobTracker examina el estado de los nodos esclavos y las colas de todas las tareas de mapas y reducen las tareas para su ejecución.
Como ranuras de procesamiento estén disponibles en los nodos esclavos, tareas mapa se implementan en los nodos esclavos.
Mapa tareas asignadas a los bloques específicos de datos se asignan a los nodos donde se almacena la misma información.
El progreso de la tarea monitores JobTracker, y en el caso de fallo de la tarea o un fallo de nodo, la tarea se reinicia en la siguiente ranura disponible.
Si la misma tarea falla después de cuatro intentos (que es un valor por defecto y se puede personalizar), todo el trabajo se producirá un error.
Después de que el mapa de tareas están terminadas, reducen las tareas de procesar los conjuntos de resultados provisionales de las tareas de mapas.
El conjunto de resultados se devuelve a la aplicación cliente.
Aplicaciones más complejas pueden tener múltiples rondas de map / reduce fases, donde el resultado de la primera ronda se utiliza como entrada para la segunda ronda. Esto es muy común con las cargas de trabajo de estilo SQL, en las que hay, por ejemplo, se unen y el grupo por operaciones.
-
 Procesamiento distribuido con MapReduce Hadoop
Procesamiento distribuido con MapReduce Hadoop - Los factores que aumentan la escala de análisis estadístico en hadoop
-
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación -
 alta disponibilidad") Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad
Hadoop distribuido sistema de archivos (HDFS) alta disponibilidad -
 Hadoop MapReduce para grandes datos
Hadoop MapReduce para grandes datos -
 ¿Cómo poner en marcha una aplicación basada hilo
¿Cómo poner en marcha una aplicación basada hilo
La API de MapReduce está escrito en Java, por lo que las aplicaciones MapReduce son principalmente basados en Java. La siguiente lista especifica los componentes de una aplicación MapReduce que se puede desarrollar:Conductor (obligatorio):…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
A diferencia de otros componentes HILO (otro negociador de recursos aún), ningún componente en Hadoop 1 asigna directamente al Maestro de aplicaciones. En esencia, este es un trabajo que el JobTracker hizo para cada aplicación, pero la…
El componente central de hilo (Sin embargo, otro negociador de recursos) es el Administrador de recursos, que regula todos los recursos de procesamiento de datos en el cluster Hadoop. En pocas palabras, el Administrador de recursos es un programador…
Cada nodo esclavo En otro negociador de recursos (HILO) tiene un demonio del administrador de Nodo, que actúa como un esclavo para el Administrador de recursos. Al igual que con la TaskTracker, cada nodo esclavo tiene un servicio que une al…