Lleve un registro de los bloques de datos con NameNode en HDFS
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas. Cuando un usuario almacena un archivo en HDFS, el archivo se divide en bloques de datos, y tres copias de estos bloques de datos se almacenan en nodos esclavos en todo el clúster Hadoop.
Conteúdo
Eso es un montón de bloques de datos para seguir la pista. Como era de esperar, saber dónde están enterrados los cuerpos hace que la NameNode un componente de vital importancia en un clúster Hadoop. Si el NameNode no está disponible, las aplicaciones no pueden acceder a los datos almacenados en HDFS.
Si usted echa un vistazo a la siguiente figura, se puede ver el demonio NameNode se ejecuta en un servidor de nodo maestro. Toda la información de mapeo tratar con los bloques de datos y sus correspondientes archivos se almacena en un archivo llamado.
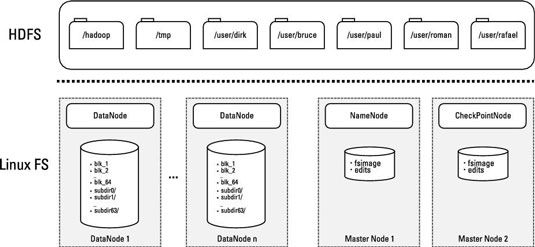
HDFS es un sistema de archivos de diario, lo que significa que cualquier cambio de datos se registran en una revista de edición que sigue los acontecimientos desde la última control - la última vez cuando el registro de edición se fusionó con. En HDFS, la revista de edición se mantiene en un archivo con el nombre que se almacena en el NameNode.
Puesta en marcha y operación de NameNode
Para entender cómo funciona el NameNode, es útil echar un vistazo a la forma en que se pone en marcha. Debido a que el propósito de la NameNode es informar a las aplicaciones de cuántos bloques de datos que necesitan para procesar y hacer un seguimiento de la ubicación exacta donde están almacenados, necesita todas las asignaciones de lugares de bloque y bloque a archivo que están disponibles en RAM.
Estos son los pasos que el NameNode toma. Para cargar toda la información que el NameNode necesita después de que se pone en marcha, sucede lo siguiente:
El NameNode carga el archivo en la memoria.
El NameNode carga el archivo y re-interpreta los cambios registrados por diario para actualizar los metadatos de bloques que ya está en la memoria.
Los demonios DataNode envían los informes de bloque NameNode.
Para cada nodo esclavo, hay un informe de bloques que muestra todos los bloques de datos almacenados allí y describe la salud de cada uno.
Una vez completado el proceso de inicio, el NameNode tiene una visión completa de todos los datos almacenados en HDFS, y está listo para recibir solicitudes de aplicaciones de los clientes de Hadoop.
A medida que se agregan y quitan los archivos de datos en base a solicitudes de los clientes, los cambios se escriben en los volúmenes de disco del nodo esclavo, se hacen cambios de diario para el archivo, y los cambios se reflejan en los lugares de bloque y los metadatos almacenados en la memoria del NameNode.
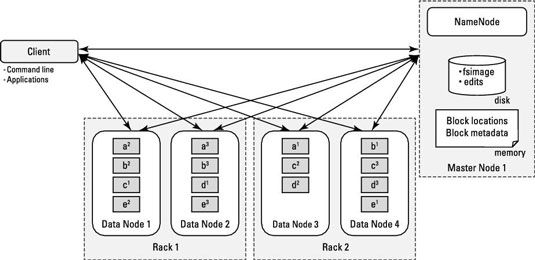
A lo largo de la vida del grupo, los demonios DataNode envían los latidos NameNode (una señal rápida) cada tres segundos, lo que indica que están activas. (Este valor predeterminado es configurable.) Cada seis horas (de nuevo, un defecto configurable), los DataNodes envían el NameNode un informe con bloques que bloquea archivos están en sus nodos. De esta manera, el NameNode siempre tiene una visión actual de los recursos disponibles en el clúster.
La escritura de datos
Para crear nuevos archivos en HDFS, el siguiente proceso tendría que tener lugar:
El cliente envía una solicitud a la NameNode para crear un nuevo archivo.
El NameNode determina cuántos se necesitan bloques, y el cliente se concede una arrendamiento para la creación de estos nuevos bloques de archivos del clúster. Como parte de este contrato, el cliente tiene un límite de tiempo para completar la tarea de creación. (Este límite de tiempo se asegura de que el espacio de almacenamiento no es absorbido por las aplicaciones cliente fallidos.)
El cliente, a continuación, escribe las primeras copias de los bloques de archivos a los nodos esclavos utilizando el contrato asignado por el NameNode.
El NameNode maneja solicitudes de escritura y determina donde los bloques de archivos y sus réplicas deben ser por escrito, el equilibrio de la disponibilidad y el rendimiento. La primera copia de un bloque de archivo se escribe en un estante, y la segunda y tercera copias están escritos en un estante diferente de la primera copia, pero en diferentes nodos esclavos en el mismo rack. Esta disposición minimiza el tráfico de red al mismo tiempo asegurar que no hay bloques de datos están en el mismo punto de falla.
Como cada bloque está escrito para HDFS, un proceso especial escribe los restantes réplicas a los otros nodos esclavos identificados por la NameNode.
Después de que los demonios DataNode reconocen el archivo réplicas de bloques se han creado, la aplicación cliente cierra el archivo y notifica al NameNode, que luego se cierra el contrato abierto.
Lectura de datos
Para leer los archivos de HDFS, el siguiente proceso tendría que tener lugar:
El cliente envía una solicitud a la NameNode para un archivo.
El NameNode determina qué bloques están involucrados y decide, basándose en la proximidad general de los bloques entre sí y para el cliente, la ruta de acceso más eficiente.
El cliente accede a los bloques usando las direcciones indicadas por el NameNode.
Equilibrio de datos en el cluster Hadoop
Con el tiempo, con combinaciones de patrones de datos de ingestión irregulares (donde algunos nodos esclavos pudieran tener más datos escritos en ellas) o errores de nodo, los datos es probable que se convierta desigualmente distribuida entre los bastidores y los nodos esclavos en el clúster Hadoop.
Esta distribución desigual puede tener un impacto negativo en el rendimiento debido a que la demanda de nodos esclavos individuales se convertirá nodos unbalanced- con pocos datos no serán plenamente Usa-y nodos con serán usados en exceso muchos bloques. (Nota: El uso excesivo y la infrautilización se basan en la actividad del disco, no en la CPU o RAM.)
HDFS incluye una utilidad equilibrador redistribuir cuadras de nodos esclavos usados en exceso a infrautilizadas queridos mientras se mantiene la política de poner bloques en diferentes nodos esclavos y bastidores. Hadoop administradores deben revisar regularmente HDFS salud, y si los datos se distribuye de manera desigual, deben invocar la utilidad equilibrador.
Diseño de servidor maestro NameNode
Debido a su naturaleza de misión crítica, el servidor principal que ejecuta el daemon NameNode necesita marcadamente diferentes requisitos de hardware que las que para un nodo esclavo. Más significativamente, los componentes a nivel de empresa deben ser utilizados para reducir al mínimo la probabilidad de una interrupción. Además, tendrá suficiente memoria RAM para cargar en la memoria de todos los datos de metadatos y la ubicación de todos los bloques de datos almacenados en HDFS.
-
 3 configuraciones de clúster Hadoop
3 configuraciones de clúster Hadoop -
 Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop
Actualizaciones de puntos de control en el sistema de archivos distribuido hadoop -
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) -
 Procesamiento distribuido con MapReduce Hadoop
Procesamiento distribuido con MapReduce Hadoop -
 Nodos de borde en racimos de Hadoop
Nodos de borde en racimos de Hadoop - Comandos de administración de Hadoop
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
A menudo en la infancia de Hadoop, una gran cantidad de debate se centra en la representación de la NameNode de un único punto de fallo. Hadoop, en general, ha tenido siempre una arquitectura robusta y el fracaso-tolerante, con la excepción de…
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el…
Para mostrar cómo los distintos HILO (otro negociador de recursos) los componentes trabajan juntos, se puede caminar a través de la ejecución de una aplicación. Por el bien del argumento, que puede ser una aplicación de MapReduce, con la…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
Al igual que la muerte y los impuestos, fallos de disco (y dado el tiempo suficiente, incluso errores de nodo o bastidor), son inevitables en Hadoop Distributed File System (HDFS). En el ejemplo mostrado, incluso si un rack fallara, el grupo podría…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…