Nodos esclavos en racimos de Hadoop
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:
NodeManager: Coordina los recursos para un nodo esclavo individual y los informes de nuevo al Administrador de recursos.
ApplicationMaster: Rastrea el progreso de todas las tareas que se ejecutan en el clúster Hadoop para una aplicación específica. Para cada aplicación cliente, el Administrador de recursos despliega una instancia del servicio ApplicationMaster en un contenedor en un nodo esclavo. (Recuerde que cualquier nodo que ejecuta el servicio NodeManager es visible para el Administrador de recursos.)
Contenedor: Una colección de todos los recursos necesarios para ejecutar las tareas individuales para una aplicación. Cuando una aplicación se está ejecutando en el clúster, los horarios del Administrador de recursos de las tareas de la aplicación que se ejecuten como servicios de contenedores en nodos esclavos del cluster.
TaskTracker: Gestiona el mapa individual y reducir las tareas que se ejecutan en un nodo esclavo para Hadoop 1 clusters. En Hadoop 2, este servicio es obsoleto y ha sido sustituido por los servicios de hilo.
DataNode: Un servicio HDFS que permite al NameNode a los bloques de tiendas en el nodo esclavo.
RegionServer: Almacena los datos para el sistema HBase. En Hadoop 2, HBase utiliza Hoya, que permite a las instancias RegionServer que se ejecutan en los contenedores.
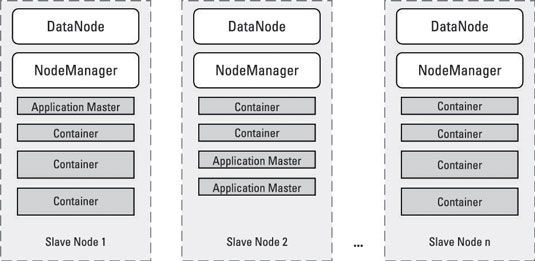
Aquí, cada nodo esclavo siempre se está ejecutando una instancia DataNode (que permite HDFS para almacenar y recuperar los bloques de datos en el nodo esclavo) y una instancia NodeManager (que permite que el Administrador de recursos para asignar tareas de aplicación al nodo esclavo para el procesamiento). Los procesos de contenedor son tareas individuales para las aplicaciones que se ejecutan en el clúster.
Cada aplicación que se ejecuta tiene una tarea ApplicationMaster dedicado, que también se ejecuta en un recipiente, y un seguimiento de la ejecución de todas las tareas que se ejecutan en el clúster hasta que se termine la aplicación.
Con HBase en Hadoop 2, el modelo de contenedor está siendo seguido, como se puede ver:
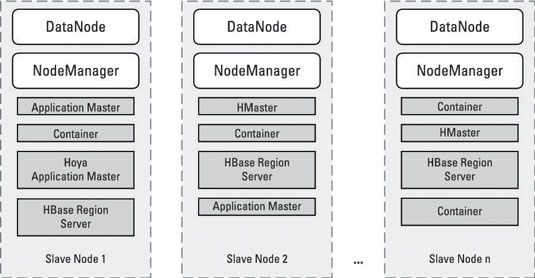
HBase en Hadoop 2 se inicia por la Hoya de aplicaciones Maestro, que solicita contenedores para los servicios HMaster. (Necesitas múltiples servicios HMaster para la redundancia.) La Hoya Aplicación Maestro también solicita recursos para RegionServers, que también se ejecutan en contenedores especiales.
La siguiente figura muestra los servicios desplegados en nodos Hadoop 1 de esclavos.
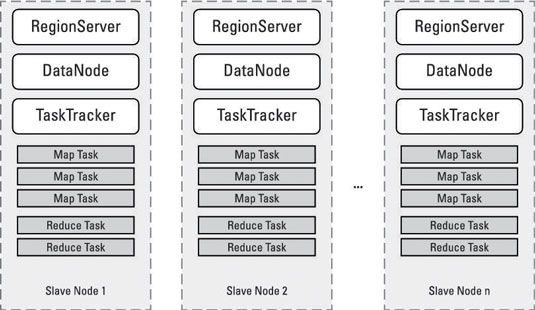
Para Hadoop 1, cada nodo esclavo siempre se está ejecutando una instancia de DataNode (que permite HDFS para almacenar y recuperar bloques de datos en el nodo esclavo) y una instancia de TaskTracker (que permite que el JobTracker para asignar mapa y reducir las tareas para el nodo esclavo para el procesamiento) .
Nodos esclavos tienen un número fijo de mapa ranuras y reducen ranuras para la ejecución del mapa y reducen las tareas respectivamente. Si el clúster ejecuta HBase, necesitará un número de sus nodos esclavos para ejecutar un servicio RegionServer. Cuantos más datos se almacenan en HBase, los más instancias RegionServer tendrás.
Los criterios de hardware para nodos esclavos son bastante diferentes de los de maestro nodes- de hecho, los criterios no coinciden con los encontrados en arquitecturas de referencia de hardware tradicionales para servidores de datos. Gran parte de los rumores que rodean Hadoop se debe al uso de hardware de los productos básicos en los criterios de diseño de los clusters Hadoop, pero tenga en cuenta que mercancía el hardware no se refiere al hardware del consumidor-grado.
Nodos esclavos Hadoop todavía requieren hardware de nivel empresarial, pero en el extremo inferior del espectro de costes, especialmente para el almacenamiento.



 federación")
 alta disponibilidad")
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
Para ver cómo el JobTracker y TaskTracker trabajan juntos para llevar a cabo una acción de MapReduce, echar un vistazo a la ejecución de una aplicación de MapReduce. La figura muestra las interacciones, y la siguiente lista de pasos establece el…
Para mostrar cómo los distintos HILO (otro negociador de recursos) los componentes trabajan juntos, se puede caminar a través de la ejecución de una aplicación. Por el bien del argumento, que puede ser una aplicación de MapReduce, con la…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
El NameNode actúa como la libreta de direcciones para Hadoop Distributed File System (HDFS), ya que no sólo sabe que bloquea constituyen archivos individuales, sino también el lugar donde se almacenan cada uno de estos bloques y sus réplicas.…
Planificación de tareas y seguimiento de los grandes datos son partes integrales de Hadoop MapReduce y se pueden usar para administrar los recursos y aplicaciones. Las primeras versiones de Hadoop apoyaron un sistema de seguimiento de trabajos y…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
Dimensionamiento cualquier sistema de procesamiento de datos es tanto una ciencia como un arte. Con Hadoop, se tiene en cuenta la misma información que lo haría con una base de datos relacional, por ejemplo. Lo más significativo es lo que…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…
A diferencia de otros componentes HILO (otro negociador de recursos aún), ningún componente en Hadoop 1 asigna directamente al Maestro de aplicaciones. En esencia, este es un trabajo que el JobTracker hizo para cada aplicación, pero la…