La agrupación en nosql
Bases de datos NoSQL son muy adecuados para grandes bases de datos. Clones BigTable como HBase no son una excepción. Es probable que desee utilizar varios servidores de las materias primas de bajo costo en un solo grupo en lugar de una máquina muy potente. Esto es porque usted puede obtener un mejor rendimiento general por dólar mediante el uso de varios servidores de las materias primas, en lugar de un servidor potente sola mucho más costoso.
Además de ser capaz de escalar rápidamente, servidores de las materias primas de bajo costo también puede hacer que su servicio de base de datos más resistentes y por lo tanto ayudar a evitar los fallos de hardware. Esto es porque usted tiene otros servidores para hacerse cargo del servicio, si la placa base del único servidor falla. Este no es el caso con un único servidor grande.
La figura muestra una configuración HBase altamente disponible con un ejemplo de datos divididos entre los servidores.
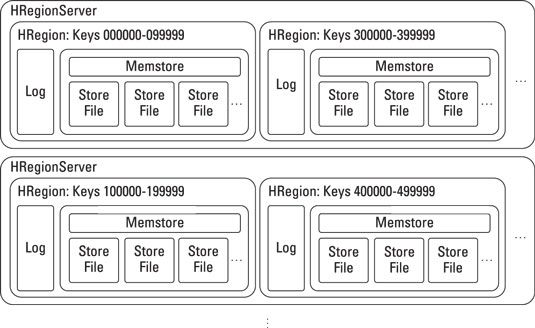
El diagrama muestra dos nodos (HRegionServers) en una configuración de alta disponibilidad, actuando cada uno como una copia de seguridad para el otro.
En muchas configuraciones de producción, es posible que desee al menos tres nodos de alta disponibilidad para asegurar dos fallas en el servidor cercanos en el tiempo entre sí se pueden manejar. Esto no es tan raro como se podría pensar! Consejos varía según Bigtable- por ejemplo, HBase recomienda cinco nodos como un mínimo para un clúster:
Cada servidor de la región maneja su propio juego de llaves.
El diseño de una estrategia de # 8208-asignación de clave de fila es importante porque dicta cómo la carga se distribuye en todo el clúster.
| Cada región mantiene su propio registro de escritura y en el # 8208-tienda de la memoria.
En HBase, todos los datos se escriben en una tienda en el # 8208-memoria, y más tarde esta tienda se vacía en el disco. En el disco, estas tiendas se llaman almacenar archivos.
HBase interpreta almacenar archivos como archivos individuales, pero en realidad, están distribuidos en trozos a través de un sistema de archivos distribuido Hadoop (HDFS). Esto proporciona una alta ingesta y velocidad de recuperación porque todas las grandes operaciones de E / S se propagan a través de muchas máquinas.
Para maximizar la disponibilidad de los datos, de forma predeterminada, Hadoop mantiene tres copias de cada archivo de datos. Instalaciones grandes tienen
Una copia primaria
Una réplica en el mismo rack
Otra réplica en un bastidor diferente
Antes de Hadoop 2.0, Namenodes no se podía hacer de alta disponibilidad. Estos mantienen una lista de todos los servidores activos en el clúster. Eran, por tanto, un único punto de fallo. Desde Hadoop 2.0, este límite ya no existe.



 federación")
 alta disponibilidad")
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
HBase y la tecnología de base de datos relacional (como Oracle, DB2, MySQL y por nombrar sólo algunos) realmente no se pueden comparar del todo bien. A pesar del cliché , es realmente un caso de comparar manzanas con naranjas. HBase es una NoSQL…
Capacidades de lectura rápidas clave-valor tiendas 'se derivan de su uso de teclas bien definidos. Estas teclas son típicamente hash, lo que da un almacén de claves-valor de una forma muy predecible de determinar qué partición (y por lo tanto…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
Los nodos principales en racimos de Hadoop distribuidos reciban a los diferentes servicios de almacenamiento y gestión de procesamiento, que se describen en esta lista, por todo el clúster Hadoop. La redundancia es fundamental para evitar los…
RegionServers son una cosa, pero también hay que echar un vistazo a cómo funcionan las distintas regiones. En HBase, una mesa es a la vez la propagación a través de una serie de RegionServers además de estar constituida por regiones…
RegionServers son los procesos de software (a menudo llamados demonios) que activan para almacenar y recuperar datos en HBase (Hadoop base de datos). En entornos de producción, cada RegionServer se implementa en su propio nodo de cómputo dedicado.…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Una característica común de los sistemas NoSQL es su capacidad para escalar a través de muchos servidores de las materias primas. Estas plataformas relativamente baratos significan que usted puede ampliar las bases de datos mediante la adición…
En un clúster Hadoop, cada nodo de datos (también conocido como un nodo esclavo) Se ejecuta un proceso de fondo llamado DataNode. Este proceso de fondo (también conocido como una demonio) Comprueba los trozos de datos que el sistema almacena en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…