Regiones en HBase
RegionServers son una cosa, pero también hay que echar un vistazo a cómo funcionan las distintas regiones. En HBase, una mesa es a la vez la propagación a través de una serie de RegionServers además de estar constituida por regiones individuales. Como se dividen las tablas, las divisiones se convierten en regiones. Regiones almacenan una gama de pares clave-valor, y cada RegionServer gestiona un número configurable de regiones.
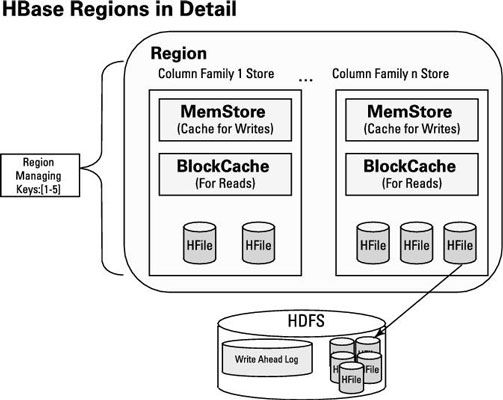
Pero lo que se ven las regiones individuales como? HBase es un almacén de datos orientada a la columna en la familia, así que ¿cómo almacenar las distintas regiones pares clave-valor en base a las familias de las columnas a las que pertenecen? La siguiente figura comienza a responder a estas preguntas y ayuda a digerir la información más vital acerca de la arquitectura de HBase.
HBase está escrito en Java - como la gran mayoría de las tecnologías de Hadoop. Java es un lenguaje de programación orientado a objetos y una tecnología elegante para la computación distribuida. Así, a medida que continúe para averiguar más sobre HBase, recuerde que todos los componentes de la arquitectura son en última instancia los objetos Java.
En primer lugar, la figura anterior da una idea bastante buena de qué región objetos parecen realmente, en términos generales. También deja claro que las regiones de datos separadas a las familias de las columnas y almacenar los datos en el HDFS utilizando objetos hFile.
Cuando los clientes ponen pares de valores clave en el sistema, las teclas se procesan de manera que los datos se almacenan sobre la base de la familia de la columna de la par pertenece. Como se muestra en la figura, cada objeto de almacén de la familia columna tiene una caché de lectura llamado BlockCache y una caché de escritura llamado MEMSTORE. El BlockCache ayuda con el rendimiento de lectura aleatoria.
Los datos se leen en cuadras del HDFS y se almacena en el BlockCache. Con posterioridad se lee de los datos - o los datos almacenados en las proximidades - se leerán de la RAM en lugar del disco, lo que mejora el rendimiento general. The Write Ahead Log (WAL, para abreviar) se asegura de que sus escrituras HBase son fiables. Hay una WAL por RegionServer.
Siempre prestar atención a la ley de hierro de la Computación Distribuida: Un fracaso no es la excepción - es la norma, sobre todo cuando la agrupación de cientos o incluso miles de servidores. Google siguió a la Ley de Hierro en el diseño BigTable y HBase siguió su ejemplo.
Al escribir o modificar datos en HBase, los datos se persistió primero a la WAL, que se almacena en el HDFS, y luego los datos se escriben en la memoria caché MEMSTORE. A intervalos configurables, pares de valores clave almacenados en el MEMSTORE se escriben en HFiles en el HDFS y posteriormente entradas WAL se borran.
Si se produce un fallo después la escritura inicial WAL pero antes de la escritura MEMSTORE final al disco, el WAL se puede reproducir para evitar cualquier pérdida de datos.
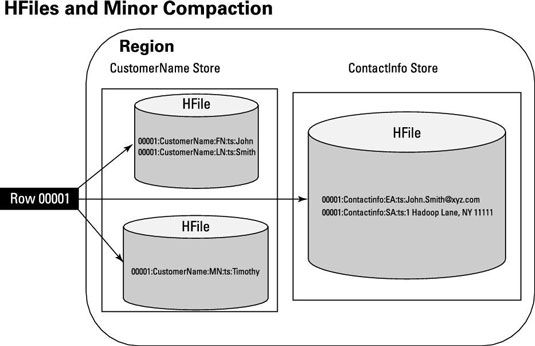
Tres objetos hFile están en una familia de la columna y dos en el otro. El diseño de HBase es para eliminar datos de la familia de columnas almacenadas en la MEMSTORE a uno hFile por descarga. A continuación, a intervalos configurables HFiles se combinan en HFiles grandes. Esta estrategia pone en cola hasta la operación de compactación crítico en HBase.



HBase y la tecnología de base de datos relacional (como Oracle, DB2, MySQL y por nombrar sólo algunos) realmente no se pueden comparar del todo bien. A pesar del cliché , es realmente un caso de comparar manzanas con naranjas. HBase es una NoSQL…
Cualquier instalación seria HBase requiere un poco de configuración estándar en el clúster y en los nodos individuales. Algunos ejemplos se proporcionan aquí. Primero eche un vistazo a la supervisión y la gestión.Herramientas para supervisar…
Sqoop se puede utilizar para transformar un esquema de base de datos relacional en un esquema HBase. Por supuesto, el objetivo principal aquí es demostrar cómo Sqoop puede importar datos de un RDBMS o almacén de datos directamente en HBase, pero…
El modelo de datos HBase lógica es simple pero elegante, y proporciona un mecanismo de almacenamiento de datos natural para todo tipo de datos - conjuntos de datos grandes, especialmente estructurados. Todas las partes del modelo de datos convergen…
RegionServers son los procesos de software (a menudo llamados demonios) que activan para almacenar y recuperar datos en HBase (Hadoop base de datos). En entornos de producción, cada RegionServer se implementa en su propio nodo de cómputo dedicado.…
Almacenes de datos HBase constan de una o más tablas, que están indexados por claves de fila. Los datos se almacenan en filas con columnas y filas puede tener múltiples versiones. Por defecto, el control de versiones de filas de datos se…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
HBase es una no relacional (columnar) base de datos distribuida, que utiliza HDFS como su almacén de persistencia para proyectos de grandes datos. Es el modelo de Google BigTable y es capaz de albergar mesas muy grandes (miles de millones de…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
HBase (Hadoop base de datos) es una implementación Java de BigTable de Google. Google define como un BigTable " escasa, distribuida, persistente mapa Ordenado multidimensional ". Es toda una definición concisa, pero también estará de acuerdo que…
HBase está escrito en Java, un lenguaje elegante para la construcción de tecnologías distribuidas como HBase, pero la cara él - no todo el mundo que quiera aprovechar las innovaciones HBase es un desarrollador Java. Es por eso que hay un rico…