El ecosistema Hadoop de Apache
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no todos) de estos proyectos están alojados por la Apache Software Foundation. La tabla muestra algunos de estos proyectos.
| Nombre del proyecto | Descripción |
|---|---|
| Ambari | Un conjunto integrado de herramientas de administración de Hadoop forinstalling, el seguimiento y el mantenimiento de un cluster Hadoop. Alsoincluded son herramientas para agregar o quitar nodos esclavos. |
| Avro | Un marco para la serialización eficiente (una oftransformation especie) de datos en un formato binario compacto |
| Flume | Un servicio de flujo de datos para el movimiento de grandes volúmenes de logdata en Hadoop |
| HBase | Una base de datos columnar distribuida que utiliza HDFS para itsunderlying almacenamiento. Con HBase, puede almacenar datos en tablas extremelylarge con estructuras de columnas variables. |
| HCatalog | Un servicio para proporcionar una vista relacional de los datos almacenados inHadoop, incluyendo un enfoque estándar para datos tabulares |
| Colmena | Un almacén de datos distribuida para los datos que se almacenan en HDFS-también proporciona un lenguaje de consulta que se basa en SQL (HiveQL) |
| Matiz | Una interfaz de administración Hadoop con herramientas visuales prácticos forbrowsing archivos, emitir consultas Colmena y cerdo, y el desarrollo de Oozieworkflows |
| Mahout | Una biblioteca de aprendizaje automático algoritmos estadísticos que wereimplemented en MapReduce y se pueden ejecutar de forma nativa en Hadoop |
| Oozie | Una herramienta de gestión de flujo de trabajo que puede manejar la programación andchaining conjunto de aplicaciones de Hadoop |
| Cerdo | Una plataforma para el análisis de grandes conjuntos de datos que Runson HDFS y con una capa de infraestructura que consiste en una compilerthat produce secuencias de programas MapReduce y un layerconsisting idioma del lenguaje de consulta llamado Pig Latin |
| Sqoop | Una herramienta para mover eficientemente grandes cantidades de datos y las bases de datos betweenrelational HDFS |
| ZooKeeper | Una interfaz sencilla para la coordinación centralizada de servicios (tales como nombres, configuración y sincronización) utiliza aplicaciones bydistributed |
El ecosistema Hadoop y sus distribuciones comerciales siguen evolucionando, con tecnologías y herramientas nuevas o mejoradas emergentes todo el tiempo.
La figura muestra los diferentes proyectos del ecosistema Hadoop y cómo se relacionan con un otro:
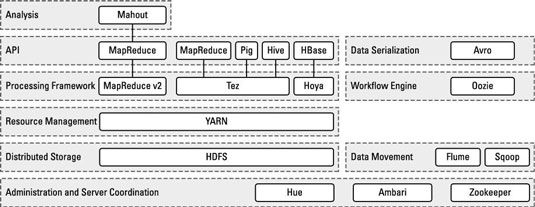

Para hacer el cuento largo, Colmena ofrece Hadoop con un puente hacia el mundo RDBMS y proporciona un dialecto SQL conocida como Hive Query Language (HiveQL), que se puede utilizar para realizar tareas tipo SQL. Esa es la gran noticia, pero hay más…
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
El poder y la flexibilidad de Hadoop para grandes datos son inmediatamente visibles para los desarrolladores de software principalmente porque el ecosistema Hadoop fue construido por los desarrolladores, para los desarrolladores. Sin embargo, no…
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.Cerdo tiene dos modos de ejecutar secuencias de comandos:Modo local: Todos…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
En 2010, EMC y VMware, los líderes del mercado en la entrega de TI como un servicio a través de la computación en nube, adquirieron Greenplum Corporation, las personas que habían llevado con éxito el producto Greenplum MPP Data Warehouse (DW)…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…