Modos locales y distribuidas de guiones de cerdos en ejecución en hadoop
Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.
Cerdo tiene dos modos de ejecutar secuencias de comandos:
Modo local: Todos los scripts se ejecutan en una sola máquina sin necesidad de Hadoop MapReduce y HDFS. Esto puede ser útil para desarrollar y probar la lógica del cerdo. Si estás usando un pequeño conjunto de datos al desarrollador o probar el código, a continuación, el modo local podría ser más rápido que ir a través de la infraestructura de MapReduce.
Modo local no requiere Hadoop. Cuando se ejecuta en modo local, el programa de cerdo se ejecuta en el contexto de una máquina virtual de Java locales, y acceso a los datos se realiza a través del sistema de archivos local de una sola máquina. Modo local es en realidad una simulación local del MapReduce en clase LocalJobRunner de Hadoop.
Modo de MapReduce (también conocido como modo Hadoop): Cerdo se ejecuta en el clúster Hadoop. En este caso, la secuencia de comandos de cerdo se convierte en una serie de trabajos de MapReduce que luego se ejecutan en el clúster Hadoop.
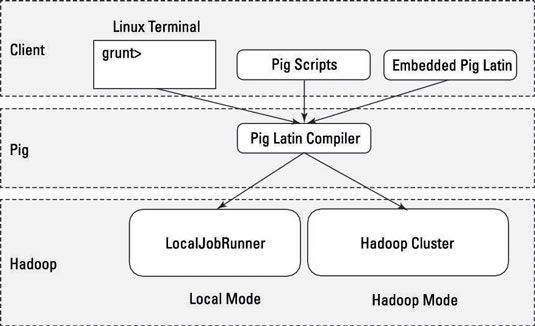
Si usted tiene un terabyte de datos que desea realizar operaciones en y desea desarrollar un programa de forma interactiva, es posible que pronto se encontrará cosas ralentizar considerablemente, y usted puede comenzar a crecer su almacenamiento. Modo local le permite trabajar con un subconjunto de sus datos de una manera más interactiva para que pueda entender la lógica (y resolver los errores) de su programa de cerdo.
Una vez que haya creado las cosas como quieres y sus operaciones están funcionando sin problemas, a continuación, puede ejecutar la secuencia de comandos en el conjunto utilizando el modo de MapReduce datos completos.


 federación")
El poder y la flexibilidad de Hadoop para grandes datos son inmediatamente visibles para los desarrolladores de software principalmente porque el ecosistema Hadoop fue construido por los desarrolladores, para los desarrolladores. Sin embargo, no…
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
El lenguaje de programación cerdo está diseñado para manejar cualquier tipo de datos arrojó su camino - estructurada, semiestructurada, los datos no estructurados, lo que sea. Programas de cerdo puede ser envasados en tres formas…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
La conversión de modelos estadísticos para funcionar en paralelo es una tarea difícil. En el paradigma tradicional para la programación en paralelo, de acceso a memoria se regula mediante el uso de hilos - subprocesos creados por el sistema…
Hadoop es un ecosistema rico y evolucionando rápidamente con un conjunto cada vez mayor de nuevas aplicaciones. En lugar de tratar de mantenerse al día con todos los requisitos para nuevas capacidades, cerdo está diseñado para ser extensible a…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Al examinar los elementos de Apache Hive muestran, se puede ver en la parte inferior que la colmena se sienta encima del Sistema Hadoop Distributed File (HDFS) y sistemas de MapReduce.En el caso de MapReduce, los figureshows tanto los componentes 1…