Bases de datos de procesamiento masivamente paralelo
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.
Apache Hive es en capas en la parte superior del sistema de Hadoop Distributed File (HDFS) y el sistema de MapReduce y presenta una interfaz de programación-SQL como a sus datos (HiveQL, para ser exactos). Esta combinación de tecnologías de Hadoop desplegado en un clúster es similar a las bases de datos del MPP que han existido por un tiempo en el mercado de TI.
Bases de datos MPP suelen proporcionar una interfaz SQL y un sistema de gestión de bases de datos relacionales (RDBMS) que se ejecuta en un clúster de servidores conectados en red entre sí por una interconexión de alta velocidad. La figura muestra los componentes de un RDBMS que normalmente se incluye en las soluciones de SQL-en-Hadoop.
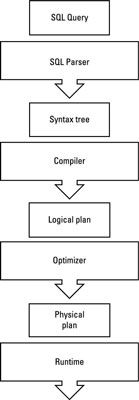
Sistemas de datos relacionales han evolucionado considerablemente a un punto donde han surgido las mejores prácticas entre la mayoría de las ofertas en términos de una infraestructura óptima ejecución de la consulta. La figura muestra esto en términos de flujo de una consulta como se procesa por un motor de RDBMS.
En primer lugar, el texto de la consulta se analiza y entiende. Entonces el árbol de sintaxis de la consulta se compila en un plan de ejecución de lógica, que a su vez está optimizada para formar el plan de ejecución física final, que luego es ejecutado por el tiempo de ejecución. Para muchas de las soluciones de SQL-en-Hadoop, que se está viendo componentes similares están desplegando en Hadoop.
Racimos MPP se refieren generalmente como teniendo una arquitectura compartida-Nada, ya que cada sistema tiene su propia CPU, memoria y disco. Sin embargo, a través del software de base de datos y de alta velocidad interconecta, las funciones del sistema en su conjunto y pueden escalar como nuevos servidores se agregan al clúster. El sistema en su conjunto se sintoniza de forma explícita para proporcionar una respuesta rápida y consulta interactiva.
Bases de datos MPP son a menudo más flexible, escalable y rentable que los RDBMS tradicionales, alojadas en un servidor multiprocesador grande.

Uno de los primeros casos de uso para Hadoop en la empresa era como un motor de transformación programática utilizada para los datos preprocess con destino a un almacén de datos. Esencialmente, este caso de uso aprovecha la potencia del…
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
IBM tiene una larga historia de trabajo con SQL y la tecnología de base de datos. De acuerdo con esta historia, la solución de IBM para SQL en Hadoop aprovecha los componentes de sus tecnologías de bases de datos relacionales que son portado para…
Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.Cerdo tiene dos modos de ejecutar secuencias de comandos:Modo local: Todos…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
En 2010, EMC y VMware, los líderes del mercado en la entrega de TI como un servicio a través de la computación en nube, adquirieron Greenplum Corporation, las personas que habían llevado con éxito el producto Greenplum MPP Data Warehouse (DW)…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
Apache Hive es indiscutiblemente la interfaz de consulta de datos más extendida en la comunidad Hadoop. Originalmente, los objetivos de diseño de la colmena no eran para la compatibilidad de SQL completa y de alto rendimiento, pero eran para…
Hay razones de peso que SQL ha demostrado ser resistente. La industria de TI ha tenido 40 años de experiencia con SQL, ya que fue desarrollado por IBM a principios de 1970. Con el aumento de la adopción de las bases de datos relacionales en la…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…