Ibm grande sql y hadoop
IBM tiene una larga historia de trabajo con SQL y la tecnología de base de datos. De acuerdo con esta historia, la solución de IBM para SQL en Hadoop aprovecha los componentes de sus tecnologías de bases de datos relacionales que son portado para correr en Hadoop.
Si usted está en todo familiarizado con nombres de productos de IBM para sus productos y características Big Data, se puede adivinar fácilmente lo que han llamado su SQL en solución Hadoop: Big SQL. El objetivo de la Gran SQL es proporcionar una interfaz SQL en Hadoop que ofrece a los usuarios la mayor cantidad posible de lo que están acostumbrados con interfaces SQL para bases de datos relacionales.
Esto significa un amplio apoyo sintaxis de consulta, un rendimiento rápido que no requiere que los usuarios tener que mono con sus consultas, y la capacidad de controlar la seguridad de datos.
La figura muestra una implementación parcial de BigInsights, distribución de Hadoop de IBM corriendo Grandes SQL.
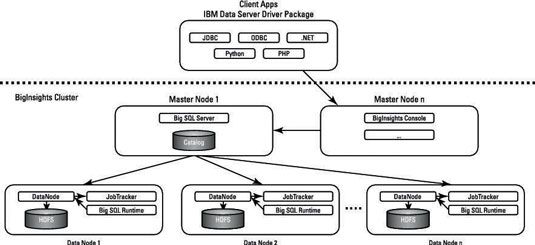
Aquí, se puede ver un subconjunto de los nodos principales y nodos de datos detrás del firewall BigInsights. Uno de los nodos maestros se está ejecutando el servidor de Big SQL, que incluye el compilador de SQL de IBM y optimizador. También se incluyen en este nodo principal es un catálogo, donde se almacenan los metadatos y estadísticas acerca de los datos catalogados en HDFS para uso del compilador / optimizador.
Subsecciones de consultas se envían a los nodos de datos aplicables donde se almacenan los datos solicitados, y el tiempo de ejecución de SQL grande (que es el tiempo de ejecución de IBM SQL) ejecuta la carga de trabajo. En lugar de asignador de ejecución y los procesos reductores y persisten los archivos con conjuntos de resultados intermedios, Big SQL utiliza funcionando continuamente demonios que pasan mensajes entre sí.
Es importante señalar que los datos sean consultados son almacenados y gestionados por Hadoop. Gran SQL admite formatos de archivo estándar Hadoop - por ejemplo, fichero de recursos y parqué.
Gran SQL proporciona el mismo amplio soporte de SQL como los productos de base de datos relacional de IBM - por ejemplo, ANSI SQL-2011, y la compatibilidad de lenguaje de procedimientos SQL de IBM (SQL / PL). (En el momento de la escritura, IBM estaba trabajando en la prestación de apoyo para el dialecto SQL de Oracle y su lenguaje procedural PL / SQL.)
Junto con el motor SQL estándar IBM llegado una serie de otras capacidades, sobre todo de IBM de fila y la seguridad basada en la columna (también conocido como grano fino control de acceso, o FGAC), donde sólo los usuarios específicos pueden ser autorizados a ver ciertos conjuntos de filas de datos o columnas.
Gran SQL viene con el cliente estándar de IBM Data Server, que incluye un paquete de controladores. Aplicaciones de bases de datos tradicionales pueden conectarse al clúster Hadoop BigInsights y segura intercambiar datos cifrados a través de SSL.




La razón la gente degustar sus datos antes de ejecutar el análisis estadístico en Hadoop es que este tipo de análisis a menudo requiere importantes recursos de computación. Esto no es sólo acerca de los volúmenes de datos: hay cinco factores…
A finales del año 2010, Hadapt se formó como una puesta en marcha por dos estudiantes de la Universidad de Yale y profesor asistente de ciencias de la computación. Profesor Daniel Abadi y Kamil Bajda-Pawlikowski, estudiante de doctorado del…
Una multitud de estudios muestran que la mayoría de los datos en un almacén de datos empresariales rara vez se preguntó. Proveedores de bases de datos han respondido a estas observaciones mediante la implementación de sus propios métodos para…
La solución a la expansión de grupos de Hadoop indefinidamente es federar el NameNode. Antes de Hadoop 2 entró en escena, racimos de Hadoop tuvieron que vivir con el hecho de que NameNode coloca límites al grado en que podrían escalar. Pocos…
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Hadoop está diseñado para ser desplegado en un gran grupo de ordenadores conectados en red, con nodos maestros (que albergan los servicios que controlan el almacenamiento de Hadoop y procesamiento) y nodos esclavos (donde se almacena o trata los…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
En 2010, EMC y VMware, los líderes del mercado en la entrega de TI como un servicio a través de la computación en nube, adquirieron Greenplum Corporation, las personas que habían llevado con éxito el producto Greenplum MPP Data Warehouse (DW)…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Debido a que muchos despliegues de Hadoop existentes todavía no están utilizando embargo, otro negociador de recursos (HILO), tomar un rápido vistazo a cómo Hadoop logró su procesamiento de datos antes de los días de Hadoop 2. Concéntrese en…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
Hay razones de peso que SQL ha demostrado ser resistente. La industria de TI ha tenido 40 años de experiencia con SQL, ya que fue desarrollado por IBM a principios de 1970. Con el aumento de la adopción de las bases de datos relacionales en la…