Hadoop como un motor de pre-procesamiento de datos
Uno de los primeros casos de uso para Hadoop en la empresa era como un motor de transformación programática utilizada para los datos preprocess con destino a un almacén de datos. Esencialmente, este caso de uso aprovecha la potencia del ecosistema Hadoop para manipular y aplicar transformaciones a los datos antes de se carga en un almacén de datos.
Aunque el motor de transformación real es nuevo (es Hadoop, por lo que las transformaciones y los flujos de datos se codifican en cerdo o MapReduce, entre otros idiomas), el enfoque en sí ha estado en uso un rato con la extracción, transformación, carga procesos (ETL).
Piense en la evolución de las bases de datos OLTP y ROLAP. Muchas organizaciones con bases de datos operacionales también desplegaron los almacenes de datos. Entonces, ¿cómo los departamentos de TI obtener datos de sus bases de datos operacionales en sus almacenes de datos? (Recuerde que los datos operativos típicamente no está en una forma que se presta a análisis.)
La respuesta aquí es ETL, y como almacenes de datos aumentaron en uso e importancia, los pasos en el proceso llegó a ser bien entendido y se han desarrollado las mejores prácticas. Además, una serie de empresas de software comenzó a ofrecer soluciones ETL interesantes para que los departamentos de TI podrían minimizar su propio desarrollo de código personalizado.
El proceso básico de ETL es bastante sencillo: usted Edatos XTRACT de una base de datos operativa, Transform en la forma que necesita para su análisis y herramientas de informes y, a continuación Load estos datos en su almacén de datos.
Una variante común de ETL es ELT - Extracto, carga, y transformar. En el proceso de ELT, realizar transformaciones (en contraste con ETL) después la carga de los datos en el repositorio de destino. Este enfoque se utiliza a menudo cuando la transformación se beneficia enormemente de un motor de procesamiento de SQL muy rápido en los datos estructurados. (Bases de datos relacionales no pueden sobresalir en el procesamiento de los datos no estructurados, pero realizar un procesamiento muy rápido de - ¿adivinen qué? -. Datos estructurados)
Si los datos que está transformando está destinado a un almacén de datos, y muchas de esas transformaciones se puede hacer en SQL, puede optar por ejecutar las transformaciones en el almacén de datos en sí. ELT es especialmente atractivo si la mayor parte de su conjunto de habilidades se encuentra con herramientas basadas en SQL.
Con Hadoop ahora capaz de procesar consultas SQL, tanto ETL y cargas de trabajo ELT se pueden alojar en Hadoop. La figura muestra los servicios de ETL añadido a la arquitectura de referencia.
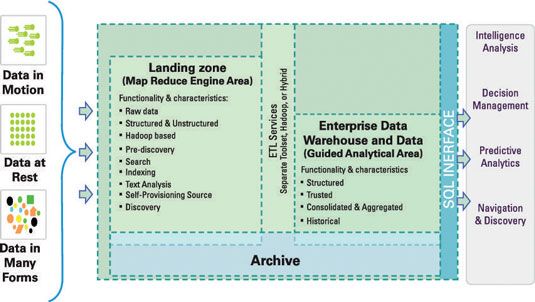
Si ha desplegado una zona de aterrizaje basado en Hadoop, tienes casi todo lo que necesita en lugar de utilizar Hadoop como motor de transformación. Ya estás aterrizando datos de sus sistemas operativos en Hadoop usando Sqoop, que cubre la etapa de extracción. En este punto tendrá que implementar su lógica transformación en MapReduce o cerdo aplicaciones. Después se transforma los datos, puede cargar los datos en el almacén de datos usando Sqoop.
El uso de Hadoop como motor de transformación de datos plantea posibilidades también. Si su almacén de datos no modifica sus datos (que es para informar solamente), sólo tiene que mantener los datos que se generan en el proceso de transformación. En este modelo, los datos sólo fluye de izquierda; a derecha en la figura, donde los datos se extrae de las bases de datos operacionales, transformado en la zona de aterrizaje, y luego cargado en el almacén de datos.
Con todos los datos transformados ya en la zona de aterrizaje, no hay necesidad de copiar de nuevo a Hadoop - a menos que, por supuesto, los datos se modificó en el almacén.



El costo económico de almacenamiento para Hadoop, más la posibilidad de consultar los datos de Hadoop con SQL hace Hadoop el principal destino para los datos de archivo. Este caso de uso tiene un bajo impacto en su organización, porque se puede…
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
Hay razones de peso que SQL ha demostrado ser resistente. La industria de TI ha tenido 40 años de experiencia con SQL, ya que fue desarrollado por IBM a principios de 1970. Con el aumento de la adopción de las bases de datos relacionales en la…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Al intentar descifrar lo que un entorno de análisis podría ser similar en el futuro, que tropieza con el patrón de la zona horaria de destino basada en Hadoop y otra vez. De hecho, ya no es ni siquiera una discusión de futuros orientado porque…
Va a encontrar valor en traer las capacidades del almacén de datos y el entorno de datos grande juntos. Es necesario crear un entorno híbrido donde los datos grandes pueden trabajar de la mano con el almacén de datos.En primer lugar, es…
Un almacén de datos tiene la distribución de datos a gran escala y tecnologías avanzadas que pueden integrar diferentes " manejar el negocio " sistemas, mejorando la calidad de los activos de datos a través de información de negocios…
Un almacén de datos es, por su propia naturaleza, un almacén de datos física distribuida. Distribución de sus activos de información ayuda en el rendimiento y la facilidad de uso a través de sistemas y en toda la empresa. Hacer este nivel de…
La organización de los servicios de datos y herramientas, la capa 3 de la pila de datos grande, capturar, validar, y montar varios elementos de datos grandes en colecciones contextualmente relevantes. Dado que los datos de grande es masiva, las…