La zona de aterrizaje basado en Hadoop
Al intentar descifrar lo que un entorno de análisis podría ser similar en el futuro, que tropieza con el patrón de la zona horaria de destino basada en Hadoop y otra vez. De hecho, ya no es ni siquiera una discusión de futuros orientado porque la zona de aterrizaje se ha convertido en el manera que las empresas a futuro ahora tratan de ahorrar costes de TI y proporcionar una plataforma para el análisis de datos innovador.
Entonces, ¿qué es exactamente la zona de aterrizaje? En el nivel más básico, el zona de aterrizaje no es más que el lugar central donde los datos aterrizarán en su empresa - extracciones semanales de los datos de las bases de datos operacionales, por ejemplo, o de los archivos de registro de generación de sistemas. Hadoop es un repositorio útil en el que a los datos de la tierra, por estas razones:
Se puede manejar todo tipo de datos.
Es fácilmente escalable.
No es caro.
Una vez que la tierra de datos en Hadoop, usted tiene la flexibilidad para consultar, analizar o procesar los datos en una variedad de maneras.
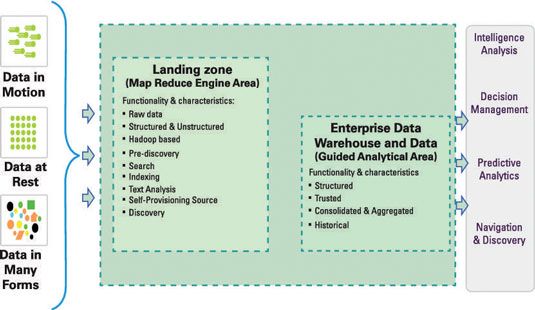
Este diagrama sólo muestra parte de la historia y es de ninguna manera completa. Después de todo, lo que necesita saber cómo los datos se mueven desde la zona de aterrizaje para el almacenamiento de datos, y así sucesivamente.
El punto de partida para la discusión sobre la modernización de un almacén de datos tiene que ser cómo las organizaciones utilizan almacenes de datos y los desafíos que los departamentos de TI se enfrentan con ellos.
En la década de 1980, una vez que las organizaciones se convirtieron en buenos en guardar su información operacional en bases de datos relacionales (transacciones de ventas, por ejemplo, o estados de la cadena de suministro), los líderes empresariales comenzaron a querer informes generados a partir de estos datos relacionales. Las primeras tiendas relacionales fueron las bases de datos operacionales y fue diseñada para el procesamiento de transacciones en línea (OLTP), por lo que los registros podrían ser insertados, actualizados o eliminados lo más rápidamente posible.
Se trata de una arquitectura poco práctico para la presentación de informes y el análisis a gran escala, por lo procesamiento analítico en línea relacional (ROLAP) bases de datos fueron desarrollados para satisfacer esta necesidad. Esto condujo a la evolución de un nuevo tipo de RDBMS conjunto: una almacén de datos, que es una entidad separada y vive junto a los almacenes de datos operativos de una organización.
Esto se reduce al uso de herramientas especialmente diseñadas para una mayor eficiencia: hay tiendas operativas de datos, que están diseñados para procesar de manera eficiente las transacciones y los almacenes de datos, que están diseñados para apoyar el análisis y elaboración de informes repetidos.
Los almacenes de datos están bajo creciente estrés, sin embargo, por las siguientes razones:
El aumento de la demanda para mantener períodos de datos más largas en línea.
La mayor demanda de recursos de procesamiento de transformar los datos para su uso en otros almacenes y mercados de datos.
La mayor demanda de análisis innovadores, que exige a los analistas a plantear preguntas sobre los datos de almacén, en la parte superior de la presentación de informes periódicos que ya se está haciendo. Esto puede incurrir en un procesamiento adicional significativo.
En la figura, se puede ver el almacén de datos se presenta como el principal recurso para los diversos tipos de análisis que aparecen en la parte derecha de la figura. Aquí puede ver también el concepto de una zona de aterrizaje representado, donde Hadoop almacenará datos de una variedad de fuentes de datos entrantes.
Para habilitar una zona de aterrizaje Hadoop, que necesita para asegurarse de que puede escribir datos de las diversas fuentes de datos a HDFS. Para bases de datos relacionales, una buena solución sería utilizar Sqoop.
Pero el aterrizaje de los datos es sólo el comienzo.
Cuando usted se está moviendo datos de muchas fuentes en su zona de aterrizaje, un tema que usted inevitablemente a tener es la calidad de los datos. Es frecuente que las empresas tienen muchas bases de datos operacionales en detalles claves son diferentes, por ejemplo, que un cliente podría ser conocido como " D. deRoos " en una base de datos, y " Dirk deRoos " en otro.
Otro problema radica en la calidad de los sistemas donde hay una fuerte dependencia de la entrada manual de datos, ya sea de clientes o personal - aquí, no es raro encontrar los nombres de pila y apellidos cambió alrededor u otra información errónea en los campos de datos.
Problemas de calidad de datos son un gran problema para los entornos de almacenamiento de datos, y es por eso que una gran cantidad de esfuerzo va en pasos de limpieza y validación como se procesan los datos de otros sistemas, ya que está cargado en la bodega. Todo se reduce a confianza: Si los datos que está haciendo preguntas en contra está sucia, no se puede confiar en las respuestas en sus informes.
Así, mientras que hay un enorme potencial en tener acceso a muchos conjuntos de datos diferentes de diferentes fuentes en su zona de aterrizaje Hadoop, hay que tener en cuenta la calidad de los datos y la cantidad que puede confiar en los datos.
-
 Integrar datos grandes con el almacén de datos tradicional
Integrar datos grandes con el almacén de datos tradicional -
 La transformación de datos en Hadoop
La transformación de datos en Hadoop -
 La modernización del almacén de datos con Hadoop
La modernización del almacén de datos con Hadoop - Los factores que aumentan la escala de análisis estadístico en hadoop
-
 Hadoop como un motor de pre-procesamiento de datos
Hadoop como un motor de pre-procesamiento de datos -
 Hadoop como destino de los datos de archivo
Hadoop como destino de los datos de archivo
Sqoop (SQL-a-Hadoop) es una herramienta de datos grande que ofrece la capacidad de extraer datos de los almacenes de datos no Hadoop, transformar los datos en una forma utilizable por Hadoop, y luego cargar los datos en HDFS. Este proceso se llama…
Dada la variedad de tipos de datos que se gestiona bases de datos NoSQL, estás perdonado si piensa que necesita tres bases de datos diferentes para gestionar todos sus datos. Sin embargo, aunque cada base de datos NoSQL tiene su público principal,…
Para proporcionar una mejor comprensión de las alternativas SQL-en-Hadoop Hive a, podría ser útil revisar una cartilla en el procesamiento paralelo masivo (MPP) bases de datos primero.Apache Hive es en capas en la parte superior del sistema de…
Almacenes de datos NoSQL originalmente suscribieron a la noción " Apenas diga no a SQL " (parafraseando a partir de una campaña publicitaria anti-drogas en la década de 1980), y eran una reacción a las limitaciones percibidas de bases de datos…
Hay razones de peso que SQL ha demostrado ser resistente. La industria de TI ha tenido 40 años de experiencia con SQL, ya que fue desarrollado por IBM a principios de 1970. Con el aumento de la adopción de las bases de datos relacionales en la…
Va a encontrar valor en traer las capacidades del almacén de datos y el entorno de datos grande juntos. Es necesario crear un entorno híbrido donde los datos grandes pueden trabajar de la mano con el almacén de datos.En primer lugar, es…
Un almacén de datos tiene la distribución de datos a gran escala y tecnologías avanzadas que pueden integrar diferentes " manejar el negocio " sistemas, mejorando la calidad de los activos de datos a través de información de negocios…
Así que, ¿qué es un almacén de datos? En un sentido literal, se describe correctamente a través de las definiciones específicas de las dos palabras que componen el término:Datos: Datos e información acerca de algoAlmacén: Una ubicación o…
Un almacén de datos es, por su propia naturaleza, un almacén de datos física distribuida. Distribución de sus activos de información ayuda en el rendimiento y la facilidad de uso a través de sistemas y en toda la empresa. Hacer este nivel de…
En el núcleo de cualquier entorno de datos grande, y la capa 2 de la pila de datos grande, son los motores de bases de datos que contienen las colecciones de elementos de datos relevantes para su negocio. Estos motores tienen que ser rápido,…
El almacén de datos, la capa 4 de la pila de datos grande, y su compañero de la despensa de datos, han sido durante mucho tiempo las técnicas primarias que las organizaciones utilizan para optimizar los datos para ayudar a los tomadores de…
Las bases de datos no relacionales no se basan en la tabla / modelo clave endémica de RDBMS (sistemas de gestión de base de datos relacional). En resumen, los datos de la especialidad en el gran mundo de los datos requiere persistencia…