Cómo detectar y prevenir cortes de salto de directorio
Salto de directorio es una debilidad muy básico, pero puede subir interesante - a veces sensible - información sobre un sistema web, por lo que es propenso a hacks. Este ataque consiste en navegar por un sitio y en busca de pistas sobre la estructura de directorios del servidor y los archivos confidenciales que podrían haber sido cargados con o sin intención.
Lleve a cabo los siguientes exámenes para determinar la información sobre la estructura de directorios de su sitio web.
Rastreadores
Un programa de araña, como el sitio web HTTrack libre copiadora, puede rastrear su sitio para buscar todos los archivos de acceso público. Para utilizar HTTrack, simplemente cargarla, dar a su proyecto un nombre, dígale HTTrack qué sitio web (s) para reflejar, y después de unos minutos, posiblemente horas, tendrá todo lo que está a disposición del público en el sitio almacenado en la unidad local en c: Mis sitios web.
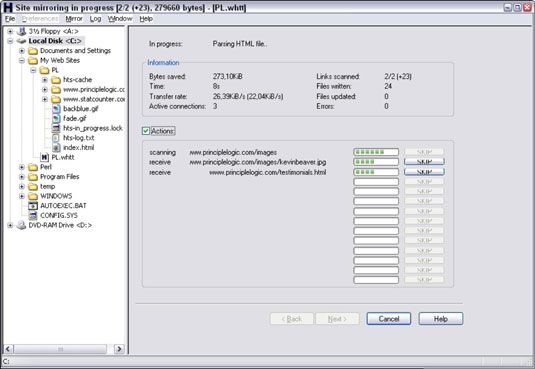
Sitios complicados suelen revelar más información que no debería estar allí, incluyendo los archivos antiguos de datos e incluso secuencias de comandos de aplicaciones y código fuente.
Inevitablemente, al realizar evaluaciones de seguridad web, por lo general hay .cremallera o .rar archivos en servidores web. A veces contienen basura, pero muchas veces se mantienen información sensible que no debería estar allí para el público para acceder.
Mira la salida de su programa de rastreo para ver lo que están disponibles los archivos. Archivos HTML y PDF regulares son probablemente bien porque están muy probablemente necesarios para uso de la web normal. Pero no estaría de más que abrir cada archivo para asegurarse de que no pertenece y no contiene información confidencial que no desea compartir con el mundo.
Google también se puede utilizar para el directorio de recorrido. De hecho, consultas avanzadas de Google son tan poderosos que puedes usarlos para erradicar a la información confidencial, los archivos y directorios del servidor web críticos, números de tarjetas de crédito, webcams - básicamente cualquier cosa que Google ha descubierto en su sitio - sin tener que reflejar su sitio y tamizar a través de todo manualmente. Ya está sentado allí en el caché de Google a la espera de ver.
Los siguientes son un par de consultas avanzadas de Google que se pueden introducir directamente en el campo de búsqueda de Google:
palabras clave de nombre de host: sitio - Esta consulta busca de una palabra clave que la lista, como SSN, confidencial, tarjeta de crédito, etcétera. Un ejemplo podría ser:
sitio: principlelogic.com altavoz
filetype: sitio de archivo de extensión: nombre de host - Esta consulta busca para tipos de archivo específicos en un sitio web específico, tales como doctor, pdf, db, dbf, cremallera, y mas. Estos tipos de archivos pueden contener información sensible. Un ejemplo podría ser:
filetype: pdf sitio: principlelogic.com
Otros operadores avanzados de Google son los siguientes:
allintitle búsquedas de palabras clave en el título de una página web.
inurl búsquedas de palabras clave en la URL de una página web.
relacionada encuentra páginas similares a esta página web.
enlace muestra otros sitios que enlazan a esta página web.
Un excelente recurso para Google piratería es Google Hacking Database Johnny largo.
Cuando tamizado a través de su sitio en Google, asegúrese de buscar información sensible sobre sus servidores, red y organización de Grupos de Google, que es el archivo Usenet. Si encuentras algo que no necesita estar allí, se puede trabajar con Google para tenerlo editado o eliminado. Para obtener más información, consulte de Google Contáctenos página.
Contramedidas contra recorridos de directorio
Usted puede emplear tres medidas principales en contra de tener archivos comprometidos a través de recorridos de directorio maliciosos:
No guarde los archivos antiguos, sensibles, o de otra manera no públicas en su servidor web. Los únicos archivos que deberían estar en su / htdocs o DocumentRoot carpeta son las que se necesitan para que el sitio funcione correctamente. Estos archivos no deben contener información confidencial que usted no quiere que el mundo vea.
Configure su robots.txt presentar para evitar que los motores de búsqueda, como Google, el rastreo de las áreas más sensibles de su sitio.
Asegúrese de que su servidor web está configurado correctamente para permitir el acceso del público a sólo aquellos directorios que son necesarios para la página de Internet funcione. Privilegios mínimos son clave aquí, por lo que proporcionan el acceso sólo a los archivos y directorios necesarios para la aplicación web para llevar a cabo correctamente.
Consulte la documentación del servidor web para obtener instrucciones sobre el control de acceso público. Dependiendo de la versión del servidor web, estos controles de acceso se establecen en
los httpd.conf archivo y la .htaccess archivos de Apache.
Administrador de Internet Information Server para IIS
Las últimas versiones de estos servidores web tienen buena seguridad directorio por defecto, así, si es posible, asegúrese de que está ejecutando las últimas versiones.
Por último, considerar el uso de un honeypot motor de búsqueda, como el Google Hack Honeypot. Un honeypot atrae a usuarios maliciosos para que pueda ver cómo los chicos malos están trabajando en contra de su sitio. A continuación, puede utilizar los conocimientos que adquiera para mantenerlos a raya.
-
 Guión predeterminado hacks en aplicaciones web
Guión predeterminado hacks en aplicaciones web - Cómo utilizar la huella de planificar un hackeo ético
- Cómo descargar un sitio web existente en Dreamweaver
- Cómo sincronizar archivos tablet android con Google Drive
- Acceder a archivos de todo el mundo con Google Drive en su nexo 7
-
 Cómo implementar una insignia página en su página de marketing google +
Cómo implementar una insignia página en su página de marketing google +
Vinculación de su empresa página de Google+ a sus anuncios es una gran manera de traer más le gusta y conseguir que más gente tras la presencia de su marca en Google+. Mediante la adición de una página de Google+ a su anuncio, está…
Puede utilizar un archivo de texto robots para bloquear una araña motor de búsqueda de rastreo de su sitio Web o una parte de su sitio. Por ejemplo, usted puede tener una versión en desarrollo de su sitio web en el que trabaja en los cambios y…
Con el fin de controlar el flujo de trabajo, Contribute instala un archivo en una carpeta específica en la raíz de cualquier sitio Web que se conecta. Este archivo, denominado archivo de configuración compartida, permite Contribute para almacenar…
Para hacer su vida más simple, Dreamweaver incorpora capacidad FTP para que pueda cargar fácilmente sus páginas a un servidor Web. La integración de esta característica también permite a Dreamweaver para ayudar a mantener un registro de los…
Después de descargar y descomprimir los archivos de Joomla, subirlas a su ISP. Hay una gran cantidad de proveedores de Internet que se pueden ejecutar Joomla. En su mayor parte, cualquier ISP que le da acceso a PHP y MySQL puede correr Joomla.Por…
Con una cuenta de Google, puedes acceder a Google Webmaster Tools y obtener una gran cantidad de información y herramientas para darle una oportunidad de luchar contra los sitios web de la competencia. Google es decididamente el rey y la reina de…
Hacer que la gente visite tu sitio Drupal es todo acerca de los medios sociales y tirando contenido de otros sitios. Últimas acciones es un módulo de Drupal que te permite publicar su contenido de medios de comunicación social en su propio sitio…
Si su proveedor de alojamiento web no está usando Fantastico o Softaculous, el primer paso para la instalación de Drupal es conseguir una copia de la última versión de Drupal y moverlo a su servidor web.Descarga del paqueteObtener una copia del…
Con Drupal 7, puede agregar módulos y temas para su sitio descargando el archivo e instalarlo manualmente. Es bueno saber cómo hacerlo usted mismo para entender cómo funciona. Instalación manual agrega algunos pasos adicionales al proceso. Estos…
Puede crear un archivo de mapas de sitio de varias maneras. Google ofrece el programa Sitemap Generator, que se puede instalar en su web en servidor es un script en Python, por lo que si usted no sabe lo que eso significa y no tiene un geek que lo…
Los motores de búsqueda reciben pistas sobre la naturaleza de un sitio a partir de su nombre de dominio, así como de la estructura de directorios y archivos del sitio. El ascensor añadido es, probablemente, no es grande, pero cada poquito cuenta,…
Usted probablemente ha visto " presentación " servicios de publicidad, tal vez en forma de spam en su bandeja de entrada, ofreciendo a presentar su sitio web a cientos de motores de búsqueda. En la mayoría de los casos, estos servicios de…