Fundamentos de Oracle Data Guard de 12c
Data Guard es cierto tecnología de protección de desastres de Oracle 12c. En él, usted tiene un mínimo de dos bases de datos, primaria y de espera. Data Guard tiene opciones para múltiples sitios de reserva así como una activo-activo
Conteúdo
Por activo-activo, significa que ambos / todos los sitios están arriba, correr, y accesible. Esto se opone a los sitios que tienen un lugar activo y los demás se pondrá en marcha cuando se necesitan. Este es un ejemplo de la disposición arquitectónica general.
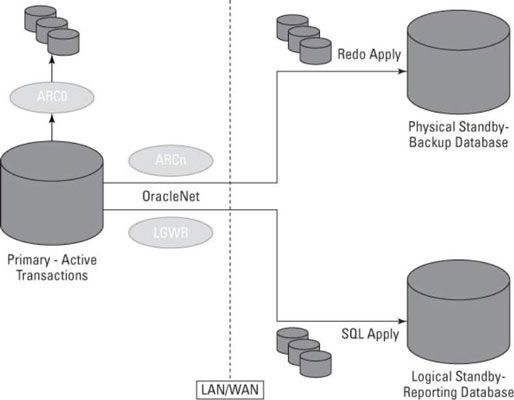
Arquitectura de Data Guard y Oracle 12c
Iniciar una descripción con la base de datos principal es fácil, ya que difiere muy poco de cualquier otra base de datos que pueda tener. La única diferencia es lo que hace con sus registros de rehacer archivados.
La base de datos principal, escribe un conjunto de registros de rehacer de archivado a un área de recuperación flash o un disco local. Sin embargo, puede configurar uno o más destinos en un entorno Data Guard.
El parámetro LOG_ARCHIVE_DEST_n puede tener este aspecto para la configuración anterior:
LOG_ARCHIVE_DEST_10 = 'UBICACIÓN = USE_DB_RECOVERY_FILE_DEST'LOG_ARCHIVE_DEST_1 =' SERVICIO = PHYSDBY1 ARCH'LOG_ARCHIVE_DEST_2 = 'SERVICIO = LGWR LOGSDBY1'
LOG_ARCHIVE_DEST_10 está configurado para enviar registros de rehacer de archivado a la zona de recuperación flash. Se requiere un destino local para todas las bases de datos del modo de registro de archivo.
LOG_ARCHIVE_DEST_1 está configurado para enviar los registros de archivos a través del proceso de archivador a un PHYSDBY1 sitio remoto. El nombre del servicio de este sitio remoto tiene una entrada en el archivo tnsnames.ora en el servidor primario.
LOG_ARCHIVE_DEST_2 está configurado para enviar los registros de archivos a través del proceso de LGWR a un sitio remoto llamado LOGSDBY1. El nombre del servicio de este sitio remoto tiene una entrada en el archivo tnsnames.ora en el servidor primario también.
¿Por qué la diferencia en comparación con los métodos de envío ARCN LGWR? Eso tiene algo que ver con los modos de protección. Un entorno Data Guard tiene tres modos de protección.
Máxima disponibilidad
El modo de protección máxima disponibilidad compromete entre el rendimiento y la disponibilidad de datos. Funciona mediante el uso de la LGWR escribir simultáneamente a rehacer los registros tanto en los sitios primarios y de reserva. La degradación del rendimiento viene en la forma de los procesos que tienen que esperar a que las entradas de registro de rehacer al ser escritos en múltiples lugares.
Sesiones emisión de confirmaciones tienen que esperar hasta que toda la información necesaria ha sido registrado en al menos una espera de registro de rehacer la base de datos. Si una sesión se cuelga debido a su incapacidad para escribir rehacer la información, el resto de la base de datos sigue avanzando.
Máxima protección
El modo de protección máxima es similar a la máxima disponibilidad, excepto que si una sesión no puede verificar que rehacer está escrito en el sitio remoto, la base de datos principal se apaga.
Configure al menos dos sitios de espera para el modo de máxima protección. De esa manera, un sitio en espera de estar disponible no interrumpir el servicio a toda la aplicación.
Este modo verifica que no hay pérdida de datos se producirá en el caso de un desastre a costa de rendimiento.
Rendimiento máximo
El modo de máximo rendimiento de la protección separa el proceso de trasvase de registros de la base de datos primaria haciéndolo pasar al proceso de registro de archivo (ARCN). De esta manera, todas las operaciones en el sitio primario pueden continuar sin esperar a que las entradas de redo se escriban en rehacer los registros o rehacer el envío.
Esto se opone a registrar los modos de envío que usan el transcriptor de anotaciones para transferir transacciones. Utilizando el escritor de registro puede ralentizar el procesamiento de la transacción, ya que puede verse afectada por la disponibilidad o el rendimiento de la red.
El rendimiento máximo proporciona el más alto nivel de rendimiento en el sitio primario a expensas de divergencia de datos. Divergencia de datos se produce cuando los datos de los dos sitios "empieza a perder la sincronización. Datos redo archivo no se envía hasta que todo un registro de rehacer archivo está completo. En el peor de los casos, una pérdida de todo el sitio podría resultar en la pérdida de valor de todo un registro de rehacer archivo de datos.
Realización de las operaciones de conmutación y la conmutación por error
Se puede cambiar el procesamiento a su sitio de espera de dos maneras:
Pasar a otra cosa es un interruptor planeado que puede ocurrir si usted quiere hacer el mantenimiento en el sitio primario que le obliga a estar disponible. Esta operación puede requerir de unos minutos de tiempo de inactividad en la aplicación, pero si usted tiene que hacer el mantenimiento que dura una hora o más, el tiempo de inactividad podría valer la pena.
Esta operación se llama agraciado conmutación porque resulta el sitio principal en su espera y su sitio en espera en su primaria. También, usted puede cambiar fácilmente de nuevo al sitio principal original sin tener que volver a crearlo desde cero.
Conmutación por error se produce cuando el sitio primario ha sido comprometida de alguna manera. Tal vez fue una pérdida total de la instalación, o tal vez usted descubrió la corrupción física en un archivo de datos. No siempre, pero por lo general después de una conmutación por error, usted tiene que sea completamente re-crear el sitio primario o recuperarlo de una copia de seguridad y volver a instaurar la misma.
Por lo general, realiza una conmutación por error sólo cuando se haya determinado que la fijación de la localización primaria tendrá tiempo suficiente para que usted prefiere no tener un corte de aplicación para todo el tiempo.
Para realizar una conmutación, siga estos pasos:
En la primaria actual, inicie sesión en SQL * Plus y escriba lo siguiente:
Usted debe ver esto:
Base de datos alterada.
Cierre la base de datos principal:
Usted debe ver esto:
Base de datos de instancia closed.Database dismounted.ORACLE cerrado.
Inicie la base de datos principal en modo nomount:
Debería ver algo como esto:
Instancia ORACLE started.Total Sistema Global Area 789172224 Tamaño bytesFixed 2148552 Tamaño bytesVariable 578815800 bytesDatabase Separadores 201326592 bytes bytesRedo Buffers6881280
Monte la base de datos como un modo de espera:
Usted debe ver esto:
Base de datos alterada.
Iniciar la recuperación:
Usted ve esto:
Medios completa recuperación.
Conéctese a SQL * Plus en el modo de espera actual y escriba lo siguiente:
Usted debe ver esto:
Base de datos alterada.
Cierre la base de datos standby:
Usted debe ver esto:
Base de datos de instancia closed.Database dismounted.ORACLE cerrado.
Asegúrese de que todos los parámetros de inicialización adecuadas se establecen para esta base de datos se comporte correctamente como una primaria.
Iniciar normalmente:
Debería ver algo como esto:
Instancia ORACLE started.Total Sistema Global Area 789172224 bytesFixed Tamaño 2148552 bytesVariable Tamaño 578815800 bytesDatabase tampones 201326592 bytesRedo Buffers6881280 bytesDatabase mounted.Database abrió.
Asegúrese de que los usuarios y las aplicaciones pueden conectarse y utilizar la nueva instancia principal.
-
 Gestión automática de almacenamiento de Oracle
Gestión automática de almacenamiento de Oracle - Definiciones básicas de bases de datos e instancias en 12c oráculo
- Conceptos básicos de los archivos de registro archivado en 12c oráculo
-
 Conceptos básicos de los archivos de datos y de control en 12c oráculo
Conceptos básicos de los archivos de datos y de control en 12c oráculo - Conceptos básicos de archivos 12c oráculo
- Fundamentos de la base de datos retrospectiva oráculo de 12c
LA base de datos standby física es una copia de bloque para el bloque de la base de datos primaria 12c Oracle. Está construido de una copia de seguridad del sitio primario y es mantenido por el envío y la aplicación de los registros de archivado…
Rehacer los archivos de registro almacenar la información de la memoria intermedia de registro en la base de datos Oracle 12c. Están escritos por el Escritor Conectarse (LGWR). Una vez más, no se puede leer estos archivos binarios sin la ayuda…
La página de configuración dentro de las bases de datos Oracle 12c le permite monitorear y hacer algunos ajustes en los parámetros de inicialización y componentes de memoria. También le permite ver las características de base de datos de uso y…
En Oracle 12c, usted puede tener más de 200 procesos en segundo plano. Dice " sobre 200 " porque varía según el sistema operativo. Si esto suena como mucho, no te asustes. Muchos son múltiplos de un mismo proceso (por paralelismo y tomar ventaja…
los Sistema Global Area (SGA) es un grupo de estructuras de memoria compartida dentro de Oracle 12c. Contiene cosas como datos y SQL. Es compartido entre procesos en segundo plano de Oracle y los procesos del servidor.El SGA se compone de varias…
Antes de crear directrices para reducir el riesgo de pérdida de datos y la corrupción en su base de datos 12c Oracle o tomar las medidas necesarias para recuperar la información rápidamente, usted tiene que entender lo que está en contra. Un…
Antes de iniciar o detener una instancia de base de datos Oracle 12c, se deben cumplir una serie de requisitos medioambientales. Estos requisitos de entorno le consiguen iniciado sesión en el servidor como el usuario correcto con las variables de…
Ciertos archivos de la base de datos pueden cambiar completamente la forma en su base de datos Oracle 12c se comporta. Pueden influir en todo, desde el rendimiento y puesta a punto, así como la resolución de problemas. El mantenimiento y la…
Si no lo ha hecho, lo que permite el sistema para archivar su 12c Oracle es un proceso muy simple. Sin embargo, mantener estas cosas en mente:Usted tiene que apagar y reiniciar la base de datos.Debe tener suficiente espacio para almacenar sus…
Hay varias razones por su base de datos Oracle 12c puede realiza a pocas cuadras de la carretera antes de ejecutar sin problemas. Pero no se preocupe, hay soluciones fáciles para estos bloques de camino! Algunas de estas razones están relacionadas…
En realidad no Empezar una base de datos Oracle 12c por se- iniciar la instancia. LA base de datos se define como los archivos reales de datos, índices, rehacer, temporales, y de control que existen en el sistema de archivos. los ejemplo se compone…
Así como existe un orden de eventos a partir de una instancia de base 12c de Oracle, también existe una orden de cómo se detiene una instancia de base de datos. Idealmente, esto es lo que sucede durante una parada de base de datos:Se les niega…