Rendimiento y grandes datos
Simplemente tener un equipo más rápido no es suficiente para garantizar el nivel adecuado de rendimiento para manejar grandes volúmenes de datos. ¡Tienes que ser capaz de distribuir los componentes de su servicio de datos grande a través de una serie de nodos. En computación distribuida, un nodo es un elemento de contenido dentro de un grupo de sistemas o dentro de un rack.
Un nodo típicamente incluye CPU, la memoria, y algún tipo de disco. Sin embargo, un nodo también puede ser una hoja de CPU y la memoria que se basan en las inmediaciones de almacenamiento dentro de un rack.
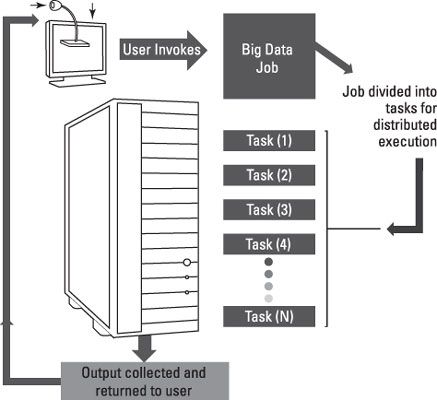
Dentro de un entorno de datos grande, estos nodos están normalmente agrupados juntos para proporcionar escala. Por ejemplo, usted podría comenzar con un análisis de datos grandes y continuar agregando más fuentes de datos. Para acomodar el crecimiento, una organización simplemente añade más nodos en un cluster para que pueda escalar para adaptarse a los requisitos de crecimiento.
Sin embargo, no es suficiente simplemente ampliar el número de nodos en el cluster. Más bien, es importante ser capaz de enviar parte del análisis de datos grande para diferentes entornos físicos. Cuando usted envía estas tareas y la forma en que administra los hace la diferencia entre el éxito y el fracaso.
En algunas situaciones complejas, es posible que desee ejecutar muchos algoritmos diferentes en paralelo, incluso dentro del mismo grupo, para alcanzar la velocidad de análisis requerido. ¿Por qué ejecutar diferentes algoritmos de datos grandes en paralelo dentro del mismo rack? Cuanto más cerca estén las distribuciones de funciones son, más rápido se pueden ejecutar.
Aunque es posible distribuir el análisis de grandes datos a través de redes para aprovechar la capacidad disponible, usted debe hacer este tipo de distribución basado en requisitos de desempeño. En algunas situaciones, la velocidad de procesamiento tiene un asiento trasero. Sin embargo, en otras situaciones, obtener resultados rápido es el requisito. En esta situación, usted quiere asegurarse de que las funciones de red están muy cerca el uno al otro.
En general, el entorno de datos grande tiene que ser optimizado para el tipo de tarea de análisis. Por lo tanto, la escalabilidad es el eje central de la toma de datos de grandes operan con éxito. Aunque sería teóricamente posible operar un entorno de datos grande dentro de un solo entorno grande, no es práctico.
Para entender las necesidades de escalabilidad de datos grandes, uno sólo tiene que mirar a la escalabilidad nube y comprender tanto los requisitos y el enfoque. Al igual que la computación en nube, big data requiere la inclusión de redes rápidas y clusters de bajo costo de hardware que se pueden combinar de bastidores para aumentar el rendimiento. Estos grupos son apoyados por la automatización de software que permite escalamiento dinámico y equilibrio de carga.
El diseño y la implementación de MapReduce son excelentes ejemplos de cómo la computación distribuida puede hacer grandes datos operacionalmente visible y asequible. En esencia, las empresas se encuentran en uno de los puntos de inflexión únicos en computación donde los conceptos de tecnología se unen en el momento adecuado para resolver los problemas correctos. Combinando la computación distribuida, los sistemas de hardware mejoradas y soluciones prácticas como MapReduce y Hadoop está cambiando la gestión de datos de manera profunda.
-
 La gestión de las tecnologías de datos grandes en una nube híbrida
La gestión de las tecnologías de datos grandes en una nube híbrida -
 Nodos de borde en racimos de Hadoop
Nodos de borde en racimos de Hadoop - Los factores que aumentan la escala de análisis estadístico en hadoop
- Hadoop empleado del zoológico de grandes datos
- Administrar los recursos de datos grandes y aplicaciones con hilo hadoop
- La gestión de grandes datos con Hadoop HDFS y MapReduce:
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Va a encontrar valor en traer las capacidades del almacén de datos y el entorno de datos grande juntos. Es necesario crear un entorno híbrido donde los datos grandes pueden trabajar de la mano con el almacén de datos.En primer lugar, es…
Dos modelos clave en la nube son importantes en la discusión de los grandes datos - nubes públicas y nubes privadas. Computación en la nube es un método para proporcionar un conjunto de recursos informáticos compartidos que incluyen…
Si su empresa está considerando un proyecto de datos grande, es importante que usted entienda algunos conceptos básicos de computación distribuida primero. No hay un modelo de computación distribuida solo porque los recursos informáticos se…
Claramente, la naturaleza misma de la nube lo convierte en un entorno de computación ideal para grandes volúmenes de datos. Entonces, ¿cómo puede usted utilizar grandes volúmenes de datos, junto con la nube? Aquí hay unos ejemplos:IaaS en una…
Aparte de la optimización del código de la aplicación actual con MapReduce para proyectos de grandes volúmenes de datos, puede utilizar algunas técnicas de optimización para mejorar la fiabilidad y el rendimiento. Se dividen en tres…
Su gran arquitectura de datos también tiene que actuar en concierto con infraestructura de apoyo de su organización. Por ejemplo, usted podría estar interesado en el funcionamiento de los modelos para determinar si es seguro para perforar en…
Computación en la nube es un método para proporcionar un conjunto de recursos informáticos compartidos y se está convirtiendo cada vez más importante para su iniciativa de datos grande. La nube incluye aplicaciones, computación,…
Con la llegada de grandes volúmenes de datos, los modelos de implementación para la gestión de datos están cambiando. El almacén de datos tradicional se lleva a cabo normalmente en un solo sistema, grande dentro del centro de datos. Los costes…
Detrás de todas las tendencias importantes en la última década, incluyendo la orientación al servicio, la computación en nube, virtualización y big data, es una tecnología fundamental llamada computación distribuida. En pocas palabras, sin…
El mercado de almacenamiento de datos de hecho ha empezado a cambiar y evolucionar con la llegada de grandes datos. En el pasado, simplemente no era económico para las empresas a almacenar la cantidad masiva de datos de un gran número de sistemas…
Muchas empresas están explorando problemas de datos grandes y dar con algunas soluciones innovadoras. Ahora es el momento de prestar atención a algunos mejores prácticas, o principios básicos, que serán muy útiles a medida que comienza su…