Datos columnares en nosql
Tiendas de columna en NoSQL son similares en apariencia a primera DBMS relacionales tradicionales. Los conceptos de filas y columnas están todavía allí. También define las familias de columna antes de la carga de datos en la base de datos, lo que significa que la estructura de los datos debe ser conocida de antemano.
Sin embargo, las tiendas de columna organizar los datos de manera diferente que las bases de datos relacionales hacen. En lugar de almacenar datos en una fila para un acceso rápido, los datos se organizan para las operaciones de columna rápida. Esta columna # 8208 vista centrada hace tiendas columnas ideales para ejecutar funciones de agregado o para buscar registros que coincidan con varias columnas.
Las funciones de agregación son combinaciones de datos o funciones de análisis. Pueden ser tan simples como contar el número de resultados, sumando ellos, o calcular su media media. Podrían ser más compleja, aunque - por ejemplo, devolver un valor complejo que describe un rango general de tiempo.
Tiendas de columna también se les conoce como Big Tablas o clones gran mesa, lo que refleja su ancestro común, Bigtable de Google a veces.
Tal vez la diferencia clave entre las tiendas de columna y un RDBMS tradicional es que, en una tienda de la columna, cada registro (creo fila en un RDBMS) no requiere un único valor por columna. En cambio, es posible modelar las familias de las columnas. Un único registro puede consistir en un campo de ID, una familia en la columna para " al cliente " información, y otra familia columna para " para el artículo " información.
Cada una de estas familias de columna consta de varios campos. Una de estas familias de columna puede tener múltiples " filas " en su propio derecho. Información de posición de pedido, por ejemplo, tiene varias filas - uno para cada partida. Estas filas contienen datos tales como ID de artículo, cantidad y precio unitario.
Un beneficio clave de una tienda en columna sobre un RDBMS es que las tiendas de columna no requieren campos para estar siempre presente y no requieren un valor de relleno nulo en blanco como un RDBMS hace. Esta característica evita el problema de escasez de datos, conservando espacio en disco. Un ejemplo de un conjunto de datos variables y escaso se muestra aquí.
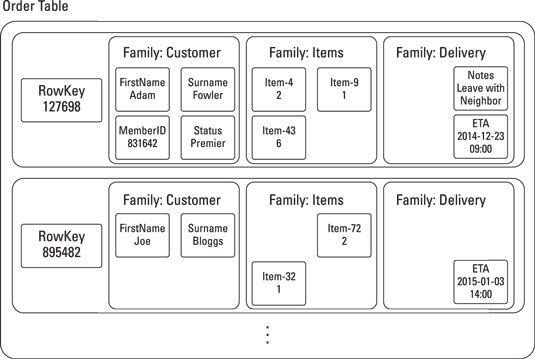
La gran cosa acerca de las tiendas de columna es que se puede recuperar toda la información relacionada con el uso de un registro único de identificación, en lugar de utilizar el complejo lenguaje de consulta estructurado (SQL) se unen como en un RDBMS. Si lo hace, requiere un poco de modelado y análisis de datos por adelantado, sin embargo.
En el ejemplo mostrado, puede recuperar toda la información del pedido seleccionando una fila única tienda de la columna, lo que significa que el desarrollador no tiene que ser consciente de la compleja exacta unirse a la sintaxis de una consulta en una tienda de la columna, a diferencia de ellos tendrían que ser utilizando SQL complejo se une a un RDBMS.
Por lo tanto, para estructuras de datos relacionales complejas y variables, una tienda de la columna puede ser más eficiente en el almacenamiento y menos propenso a errores en el desarrollo de sus antepasados RDBMS.
Tenga en cuenta que, en el artículo familia columna, ID de cada elemento está representado dentro de la clave, y el valor es la cantidad pedida. Esta configuración permite la búsqueda rápida de todos los pedidos que contienen este elemento de identificación.
Si conoces a los campos de datos que participan en la delantera y la necesidad de recuperar rápidamente datos relacionados juntos como un solo registro, y luego considerar una tienda de columna.

Bases de datos NoSQL no se restringen a un filas # 8208 y # 8208 enfoque columnas. Están diseñados para manejar una gran variedad de datos, incluidos los datos cuya estructura cambia con el tiempo y cuyas interrelaciones aún no se conocen.Bases…
Para que tu cabeza alrededor NoSQL puede ser un poco difícil. Si usted ha estudiado las bases de datos en la escuela, que puede haber sido adoctrinado en una forma relacional de pensamiento. Decir base de datos a la mayoría de la gente, y ellos…
HBase es una no relacional (columnar) base de datos distribuida, que utiliza HDFS como su almacén de persistencia para proyectos de grandes datos. Es el modelo de Google BigTable y es capaz de albergar mesas muy grandes (miles de millones de…
Un Bigtable tiene mesas al igual que un RDBMS hace, pero a diferencia de un RDBMS, unas mesas BigTable generalmente no tienen relaciones con otras tablas. En cambio, los datos complejo se agrupa en una sola tabla.Una mesa en un Bigtable consiste en…
Bases de datos de columnas pueden ser muy útiles en su proyecto de datos grande. Bases de datos relacionales son fila orientada, como los datos en cada fila de una tabla se almacena junto. En una columnar, o base de datos orientada a columnas, se…
MySQL es un sistema de gestión de bases de datos relacionales (RDBMS). El servidor MySQL puede manejar muchas bases de datos al mismo tiempo. De hecho, muchas personas pueden tener diferentes bases de datos gestionadas por un único servidor MySQL.…
Algunas tablas de una base de datos MySQL están relacionados. Muy a menudo, una fila en una tabla está relacionada con varias filas de otra tabla. Usted necesita una columna para conectar las filas relacionadas en las diferentes mesas. En muchos…
Para comenzar a trabajar en una nueva hoja de cálculo de Excel 2013, sólo tiene que empezar a introducir información en la primera hoja de la ventana del libro Libro1. Aquí están algunas pautas simples (una especie de introducción de datos de…
Para comenzar a trabajar en una nueva hoja de cálculo de Excel 2016, sólo tiene que empezar a introducir información en la primera hoja de la ventana del libro Libro1. Aquí están algunas pautas simples (una especie de introducción de datos de…
Con las tablas de datos de Excel 2007, introduce una serie de valores posibles que se conecta de Excel en una única fórmula para que pueda realizar análisis what-if en los datos. Análisis Y si le permite explorar las posibilidades de una hoja de…
Para comenzar a trabajar en una nueva hoja de cálculo de Excel 2010, sólo tiene que empezar a introducir información en la primera hoja de la ventana del libro Libro1. Aquí están algunas pautas simples (una especie de introducción de datos de…
PHP se comunica con bases de datos MySQL mediante el envío de consultas SQL. Aquí está una lista de consultas SQL, con su sintaxis, que puede utilizar para acceder, ver y modificar la base de datos:ALTER MESA el cambio de mesaCREAR BASE DE DATOS…