Cómo establecer el fundamento arquitectónico para grandes datos
Es importante establecer una base sólida arquitectura si usted quiere tener éxito con los grandes datos. Además de apoyar a los requisitos funcionales, es importante apoyar el rendimiento requerido. Sus necesidades dependerán de la naturaleza del análisis que están apoyando. Necesitará la cantidad correcta de potencia de cálculo y la velocidad.
Conteúdo
Su arquitectura también tiene que tener la cantidad adecuada de redundancia para que esté protegido de la latencia y el tiempo de inactividad imprevisto.
Comience haciéndose las siguientes preguntas:
¿Cuántos datos se su organización necesita para gestionar el presente y en el futuro?
¿Con qué frecuencia su organización necesita para administrar los datos en tiempo real o casi en tiempo real?
¿Cuánto riesgo puede darse el lujo de su organización? Es el sector sujeto a estrictas medidas de seguridad, el cumplimiento y los requisitos de gobierno?
¿Qué tan importante es la velocidad a la necesidad de gestionar los datos?
Cómo determinado o precisa que hace los datos tienen que ser?
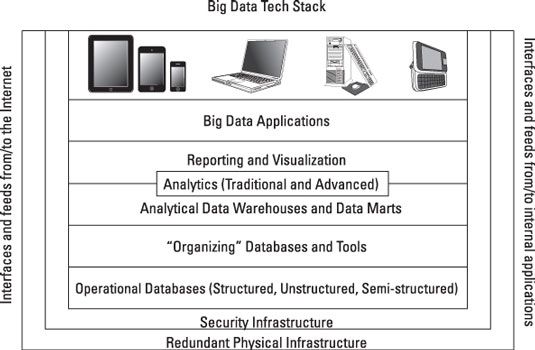
Interfaces y alimentos para grandes datos
Para entender cómo los grandes datos funciona en el mundo real, es importante comenzar por la comprensión de la necesidad de interfaces y feeds. De hecho, lo que hace que los grandes datos grande es el hecho de que se basa en recoger un montón de datos de muchas fuentes.
Por lo tanto, las interfaces de programación de aplicaciones (API) abierta será básico para cualquier arquitectura de datos grande. Además, tenga en cuenta que existen las interfaces en todos los niveles y entre todas las capas de la pila. Sin servicios de integración, los datos grandes no pueden pasar.
Infraestructura física grande de datos redundante
La infraestructura física de apoyo es fundamental para el funcionamiento y la escalabilidad de una gran arquitectura de datos. De hecho, sin la disponibilidad de las infraestructuras físicas robustas, big data probablemente no se han convertido en una tendencia tan importante. Para soportar un volumen inesperado o impredecible de los datos, una infraestructura física para grandes datos tiene que ser diferente a la de los datos tradicionales.
La infraestructura física se basa en un modelo de computación distribuido. Esto significa que los datos pueden ser almacenados físicamente en muchos lugares diferentes y pueden ser unidos entre sí a través de redes, el uso de un sistema de archivos distribuido, y varios grandes herramientas de análisis de datos y aplicaciones.
La redundancia es importante porque se trata de tantos datos de tantas fuentes diferentes. Redundancia viene en muchas formas. Si su empresa ha creado una nube privada, tendrá que contar con redundancia integrada en el entorno privado para que pueda escalar para soportar cargas de trabajo cambiantes.
Si su empresa quiere contener el crecimiento interno de TI, puede utilizar los servicios de nube externos para aumentar sus recursos internos. En algunos casos, esta redundancia puede venir en forma de software como servicio (SaaS) que permite a las empresas a hacer análisis de datos sofisticada como un servicio. El enfoque SaaS ofrece menores costos, arranque más rápido, y la evolución perfecta de la tecnología subyacente.
Infraestructura de seguridad Big Data
El análisis más importantes grandes datos convierte a las empresas, más importante será asegurar que los datos. Por ejemplo, si usted es una empresa de salud, es probable que desee utilizar aplicaciones de datos grandes para determinar los cambios en la demografía o los cambios en las necesidades del paciente. Estos datos acerca de sus componentes debe ser protegido tanto para satisfacer los requisitos de cumplimiento y para proteger la privacidad de los pacientes.
Usted tendrá que tomar en cuenta que se le permite ver los datos y en qué circunstancias se les permite hacerlo. Tendrá que ser capaz de verificar la identidad de los usuarios, así como proteger la identidad de los pacientes.
Fuentes de datos grandes operativos
Es importante entender que hay que incorporar todas las fuentes de datos que le dará una visión completa de su negocio y vea cómo los impactos de datos de la manera que opera su negocio. A medida que el mundo cambia, es importante entender que los datos operativos ahora tiene que abarcar un conjunto más amplio de fuentes de datos, incluidas las fuentes no estructuradas, tales como datos de medios sociales en todas sus formas.
Usted encontrará nuevos enfoques emergentes para la gestión de datos en el gran mundo de los datos, incluyendo documentos, gráfica, columnar, y arquitecturas de bases de datos geoespaciales. Colectivamente, estos se denominan NoSQL, o no sólo SQL, bases de datos. En esencia, es necesario asignar las arquitecturas de datos a los tipos de transacciones.
Si lo hace, le ayudará a asegurar la derecho se dispone de datos cuando lo necesite. También es necesario arquitecturas de datos que apoyan el contenido no estructurado complejo. Es necesario incluir ambas bases de datos relacionales y no relacionales de bases de datos en su enfoque para el aprovechamiento de grandes datos. También es necesario incluir fuentes de datos no estructurados, como los sistemas de gestión de contenidos, por lo que puede estar más cerca de ese punto de vista de negocio de 360 grados.
Todas estas fuentes de datos operacionales tienen varias características en común:
Representan sistemas de registro que realizan el seguimiento de los datos críticos necesarios para en tiempo real, la operación del día a día del negocio.
Se actualizan continuamente sobre la base de las transacciones que ocurren dentro de las unidades de negocio y de la web.
Para estas fuentes para proporcionar una representación exacta de la empresa, deben combinar datos estructurados y no estructurados.
Estos sistemas también deben ser capaces de escalar para soportar miles de usuarios en una base consistente. Estos pueden incluir los sistemas transaccionales de comercio electrónico, sistemas de gestión de relaciones con los clientes o aplicaciones de call center.
-
 Integrar datos grandes con el almacén de datos tradicional
Integrar datos grandes con el almacén de datos tradicional -
 Fundamentos de la infraestructura de datos grande
Fundamentos de la infraestructura de datos grande - Análisis de datos grandes y el almacén de datos
-
 Almacén de datos: fuentes de datos fuente
Almacén de datos: fuentes de datos fuente - Capa 3 de la pila de datos grande: la organización de los servicios y herramientas de datos
- La nube en el contexto de grandes datos
Con la llegada de grandes volúmenes de datos, los modelos de implementación para la gestión de datos están cambiando. El almacén de datos tradicional se lleva a cabo normalmente en un solo sistema, grande dentro del centro de datos. Los costes…
Los elementos fundamentales de la plataforma de datos grande gestionar los datos de nuevas maneras, en comparación con la base de datos relacional tradicional. Esto es debido a la necesidad de contar con la escalabilidad y alto rendimiento…
El mercado de almacenamiento de datos de hecho ha empezado a cambiar y evolucionar con la llegada de grandes datos. En el pasado, simplemente no era económico para las empresas a almacenar la cantidad masiva de datos de un gran número de sistemas…
Muchas empresas están explorando problemas de datos grandes y dar con algunas soluciones innovadoras. Ahora es el momento de prestar atención a algunos mejores prácticas, o principios básicos, que serán muy útiles a medida que comienza su…
Gran datos requiere un enfoque coherente de web y gestión de contenidos. No es ningún secreto que la mayoría de los datos disponibles en el mundo de hoy no es estructurado. Paradójicamente, las empresas han centrado sus inversiones en los…
Big Data permite a las organizaciones almacenar, gestionar y manipular grandes cantidades de datos dispares a la velocidad adecuada y en el momento adecuado. Para obtener los conocimientos adecuados, grandes datos se suelen dividirse por tres…
Gestión de datos empresariales (EDM) es un proceso importante en las grandes datos para la comprensión y el control de la economía de los datos en su empresa u organización. Aunque EDM no es necesaria para los grandes datos, la correcta…
Un enfoque reflexivo y bien gobernado a la seguridad puede tener éxito en la mitigación contra muchos riesgos de seguridad. Usted necesita desarrollar un entorno seguro de datos grande. Una cosa que puedes hacer es evaluar su estado actual.En un…
Las empresas están nadando en grandes volúmenes de datos. El problema es que a menudo no saben cómo utilizar pragmáticamente que los datos sean capaces de predecir el futuro, ejecutar procesos de negocios importantes, o simplemente obtener…
Con los desafíos de la gobernanza presentados por los grandes datos, es sabio y absolutamente necesario contar con las prácticas en el lugar para asegurarse de que usted está protegiendo su información. Si bien el grado en que lo haces éstos…
¿Cómo va a saber cómo poner todos los datos juntos? Con un proyecto de datos grande, lo que quiere hacer con sus datos estructurados y no estructurados indica por qué es posible elegir una pieza de tecnología sobre otra. También determina la…
Para entender los grandes datos, ayuda a ver cómo se acumula hasta - es decir, para diseñar los componentes de la arquitectura. Un gran arquitectura de gestión de datos debe incluir una variedad de servicios que permiten a las empresas hacer uso…