Aprendizaje con mahout en hadoop Máquina
Aprendizaje automático
se refiere a una rama de técnicas de inteligencia artificial que proporciona herramientas que permiten a las computadoras para mejorar su análisis basado en eventos anteriores. Estos datos históricos de apalancamiento sistemas informáticos de los intentos anteriores de resolver una tarea con el fin de mejorar el desempeño de los futuros intentos de tareas similares.En cuanto a los resultados esperados, aprendizaje automático puede sonar muy parecido a esa otra palabra de moda " la minería de datos " - sin embargo, el primero se centra en la predicción a través de análisis de preparado datos de entrenamiento, esta última se ocupa de descubrimiento de conocimiento a partir de sin procesar datos brutos. Por esta razón, la máquina de aprendizaje depende en gran medida de las técnicas de modelización estadística y saca de áreas de teoría de la probabilidad y reconocimiento de patrones.
Mahout es un proyecto de código abierto de Apache, ofreciendo bibliotecas Java para los algoritmos de aprendizaje automático escalables distribuidos o de otro tipo.
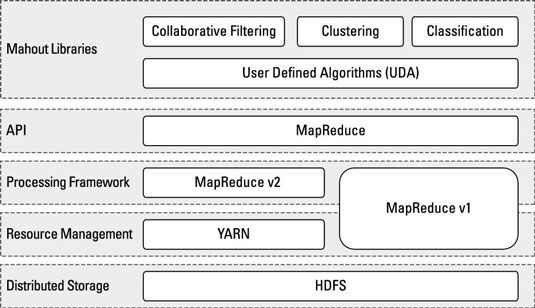
Estos algoritmos cubren tareas clásicas de aprendizaje automático como la clasificación, agrupación, el análisis de reglas de asociación, y las recomendaciones. Aunque las bibliotecas Mahout están diseñados para trabajar dentro de un contexto Hadoop, también son compatibles con cualquier sistema que soporta el marco MapReduce. Por ejemplo, Mahout proporciona bibliotecas Java para colecciones de Java y las operaciones comunes de matemáticas (álgebra lineal y estadísticas) que se pueden utilizar sin Hadoop.
Como se puede ver, las bibliotecas Mahout se implementan en Java MapReduce y se ejecutan en el clúster como colecciones de trabajos de MapReduce a cada hilo (con v2 MapReduce), o v1 MapReduce.
Mahout es un proyecto en evolución con múltiples colaboradores. En el momento de escribir estas líneas, la colección de algoritmos disponibles en las bibliotecas Mahout es de ninguna manera COMPLETE- sin embargo, la colección de algoritmos implementados para su uso continúa ampliando con el tiempo.
Hay tres categorías principales de algoritmos Mahout para apoyar el análisis estadístico: colaboración filtrado, agrupación y clasificación.
Filtrado colaborativo
Mahout fue diseñado específicamente para servir como un motor de recomendación, que emplea lo que se conoce como filtrado colaborativo algoritmo. Mahout combina la riqueza de los algoritmos de agrupación y clasificación a su disposición para producir recomendaciones más precisas sobre la base de datos de entrada.
Estas recomendaciones se aplican a menudo en contra de las preferencias del usuario, teniendo en cuenta el comportamiento del usuario. Mediante la comparación de las selecciones anteriores de un usuario, es posible identificar los vecinos más cercanos (personas con antecedentes decisión similar) a ese usuario y predecir futuras selecciones basadas en el comportamiento de los vecinos.
Considere una " degustar perfil " motor como Netflix - un motor que recomienda calificaciones basado en puntuación y visualización anteriores hábitos de ese usuario. En este ejemplo, los patrones de comportamiento de un usuario se comparan contra la historia del usuario - y las tendencias de los usuarios con gustos similares que pertenecen a la misma comunidad Netflix - para generar una recomendación para el contenido aún no visto por el usuario en cuestión.
Clustering
A diferencia del método de aprendizaje supervisado para la función de motor de recomendación de Mahout, la agrupación es una forma de sin supervisión aprendizaje - donde no se conocen de antemano las etiquetas de puntos de datos y deben deducirse de los datos sin intervención humana (la supervisados parte).
En general, los objetos dentro de un grupo deben ser objetos semejanzas de diferentes grupos deben ser diferentes. Las decisiones tomadas de antemano sobre el número de grupos para generar, los criterios para medir " similitud, " y la representación de objetos impactará el etiquetado producido por algoritmos de agrupamiento.
Por ejemplo, un motor de la agrupación que se proporciona una lista de los artículos de noticias debe ser capaz de definir grupos de artículos dentro de esa colección que discutir temas similares.
Supongamos que un conjunto de artículos sobre Canadá, Francia, China, la silvicultura, el aceite y el vino eran a agruparse. Si el número máximo de grupos se establece en 2, el algoritmo puede producir categorías como " regiones " y " # 148 industrias.; Ajustes en el número de grupos producirán diferentes categorizations- por ejemplo, la selección de 3 grupos puede resultar en grupos de pares de categorías nación de la industria.
Clasificaciones
Algoritmos de clasificación hacen uso de conjuntos de datos de entrenamiento humanos marcado, donde la categorización y clasificación de todas las entradas futuro se rige por estas etiquetas conocidas. Estos clasificadores implementar lo que se conoce como aprendizaje supervisado en la máquina del mundo de aprendizaje.
Reglas de clasificación - establecidos por los datos de entrenamiento, que ha sido etiquetados antes de tiempo por expertos de dominio - A continuación se aplican en contra, los datos crudos, sin procesar para determinar mejor su etiquetado apropiado.
Estas técnicas se utilizan a menudo por los servicios de correo electrónico que tratan de clasificar el spam de correo electrónico antes de que se crucen en tu bandeja de entrada. En concreto, teniendo en cuenta un correo electrónico que contiene un conjunto de frases que se sabe que ocurren comúnmente juntos en una cierta clase de correo spam - entregado desde una dirección que pertenece a una botnet conocida - el algoritmo de clasificación es capaz de identificar de forma fiable el correo electrónico como malicioso.
Además de la gran cantidad de algoritmos estadísticos que Mahout ofrece de forma nativa, un apoyo Algoritmos definidos por el usuario (UDA) módulo también está disponible. Los usuarios pueden anular los algoritmos existentes o implementar su propia a través del módulo de UDA. Esta personalización robusta permite la optimización del rendimiento de los algoritmos Mahout nativas y flexibilidad para hacer frente a desafíos únicos de análisis estadístico.
Si Mahout puede ser visto como una extensión de análisis estadísticos para Hadoop, UDA debe ser visto como una extensión de las capacidades estadísticas de Mahout.
Aplicaciones de análisis estadísticos tradicionales (tales como SAS, SPSS y R) vienen con potentes herramientas para la generación de flujos de trabajo. Estas aplicaciones utilizan las interfaces gráficas de usuario intuitivas que permiten la visualización de mejores datos. Guiones Mahout siguen un patrón similar al de estas otras herramientas para la generación de flujos de trabajo de análisis estadístico.
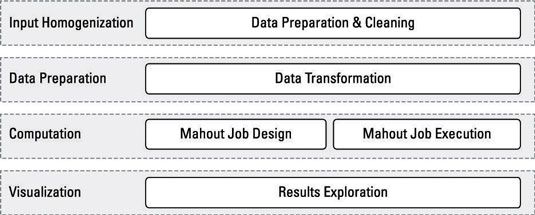
Durante la última etapa de exploración y visualización de datos, los usuarios pueden exportar a formatos legibles (JSON, CSV) o tomar ventaja de las herramientas de visualización tales como Tableau escritorio.
La arquitectura del mahout se sienta encima de la plataforma Hadoop. Hadoop desahoga el programador mediante la separación de la tarea de los trabajos de MapReduce de programación de la contabilidad compleja necesaria para gestionar el paralelismo entre los sistemas de archivos distribuidos. En el mismo espíritu, Mahout proporciona abstracciones-programador amigable de algoritmos estadísticos complejos, listos para su implementación con el marco de Hadoop.

En un principio, los grandes datos y R no eran amigos naturales. R programación requiere que todos los objetos pueden cargar en la memoria principal de una sola máquina. Las limitaciones de esta arquitectura se dieron cuenta rápidamente cuando…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
La disciplina de aprendizaje máquina tiene un catálogo rico y extenso de técnicas. Mahout trae una gama de herramientas estadísticas y algoritmos a la mesa, pero sólo capta una fracción de esas técnicas y algoritmos, ya que la tarea de…
La conversión de modelos estadísticos para funcionar en paralelo es una tarea difícil. En el paradigma tradicional para la programación en paralelo, de acceso a memoria se regula mediante el uso de hilos - subprocesos creados por el sistema…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Aprendizaje no supervisado tiene muchos retos para el análisis predictivo - incluyendo sin saber qué esperar cuando se ejecuta un algoritmo. Cada algoritmo producirá diferente en los resultados nunca estarás seguro de si un resultado es mejor…
Con un enfoque basado en el usuario de filtrado colaborativo en el análisis predictivo, el sistema puede calcular la similitud entre pares de los usuarios mediante el uso de la fórmula similitud del coseno, una técnica muy similar al enfoque…
los máquinas de vectores soporte (SVM) es un algoritmo de clasificación de datos en el análisis predictivo que asigna nuevos elementos de datos a una de las categorías marcadas. SVM es, en la mayoría de los casos, una binario classifier- se…
Varios algoritmos estadísticos, de minería de datos, y la máquina de aprendizaje están disponibles para su uso en el modelo de análisis predictivo. Usted está en una mejor posición para seleccionar un algoritmo después de que haya definido…
El algoritmo K-means requiere un parámetro de inicialización del usuario con el fin de crear una instancia de análisis predictivo. Tiene que saber cuántos K grupos a utilizar para llevar a cabo su labor.Sépalo LongitudSépalo AnchoPétalo…
En análisis supervisadas, tanto de entrada como de salida preferidos son parte de los datos de entrenamiento. El modelo de análisis predictivo se presenta con los resultados correctos como parte de su proceso de aprendizaje. Tal aprendizaje…