Operando flujos de trabajo oozie en hadoop
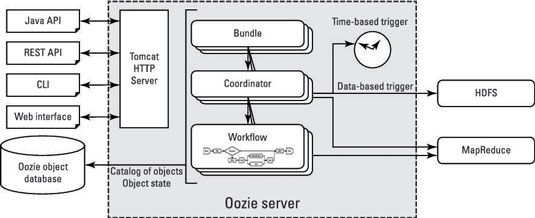
Antes de ejecutar los flujos de trabajo oozie, todos sus componentes tienen que existir dentro de una estructura de directorio especificado. En concreto, el flujo de trabajo en sí debe tener su propio directorio, dedicado, donde workflow.xml está en el directorio raíz, y existen bibliotecas de código en el subdirectorio llamado lib. El directorio de flujo de trabajo y todos sus archivos deben existir en HDFS para que pueda ser ejecutado.
Si usted va a utilizar la interfaz de línea de comandos Oozie para trabajar con varios puestos de trabajo, asegúrese de establecer la variable de entorno OOZIE_URL. (Esto se hace fácilmente desde una línea de comandos en un terminal de Linux.) Usted puede ahorrar un montón de escribir debido a la URL del servidor Oozie ahora automáticamente se incluye con sus peticiones.
Aquí hay un comando de ejemplo se podría utilizar para establecer la variable de entorno OOZIE_URL desde la línea de comandos:
exportación OOZIE_URL = "http: // localhost: 8080 / oozie"
Para ejecutar una carga de trabajo Oozie desde la interfaz de línea de comandos Oozie, ejecute un comando como el siguiente, garantizando al mismo tiempo que el archivo es job.properties localmente accesible - significa la cuenta que está utilizando se puede ver, lo que significa que tiene que estar en el mismo sistema en el que se está ejecutando Oozie comandos:
$ Job oozie -config sampleWorkload / job.properties -run
Después de enviar un trabajo, la carga de trabajo se almacena en la base de datos de objetos Oozie.
En la presentación, Oozie devuelve un identificador para que pueda monitorear y administrar el flujo de trabajo - empleo: 0000001 hasta 00000001234567-oozie-W, por ejemplo.
Para comprobar el estado de este trabajo, usted ejecuta el comando
trabajo oozie -info 0000001-00000001234567-oozie-W




HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Después de crear un conjunto de flujos de trabajo, puede utilizar una serie de puestos de trabajo de coordinador oozie para programar cuando son ejecutados. Usted tiene dos opciones de programación para la ejecución: un tiempo específico y la…
Si se siente cómodo trabajando con máquinas virtuales y Linux, no dudes en instalar Bigtop en una máquina virtual diferente a lo que se recomienda. Si usted es realmente atrevido y tener el hardware, seguir adelante y tratar de instalar Bigtop en…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Al examinar los elementos de Apache Hive muestran, se puede ver en la parte inferior que la colmena se sienta encima del Sistema Hadoop Distributed File (HDFS) y sistemas de MapReduce.En el caso de MapReduce, los figureshows tanto los componentes 1…
Si está trabajando en la Terminal en tu Mac, lo que necesita saber los más importantes comandos de UNIX: los que trabajan con los directorios, los que trabajan con archivos y comandos diversos pero de uso común.Las carpetas se denominan…
De código abierto Linux es una alternativa popular a Microsoft Windows, y si usted decide utilizar este bajo costo o sistema operativo libre, es necesario conocer algunos comandos básicos de Linux para que su sistema sin problemas. Los comandos de…
fiesta en Linux tiene más de 50 incorporados en los comandos, incluyendo comandos comunes como disco compacto y pwd, así como muchos otros que se utilizan con poca frecuencia. Puede utilizar estos comandos integrados en cualquier fiesta script o…
El examen de certificación CompTIA Linux + de cubre el tema de comandos GNU y Unix. La tabla muestra los subtemas, pesos, descripciones y áreas de conocimiento clave para este tema.Breakout de dominio 103SubtemaPesoDescripciónAreas claveEl…
El Linux hacer utilidad funciona mediante la lectura e interpretación de un makefile. Normalmente se ejecuta hacer simplemente escribiendo el siguiente comando en el intérprete de comandos:hacerCuando se ejecuta esta manera, GNU hacer busca un…
El examen de Linux Fundamentos abarca el tema de la utilización de la línea de comandos para obtener ayuda. La tabla muestra los subtemas, el peso, la descripción y las áreas de conocimiento clave para este tema.Breakout de…
Por desgracia, no se puede ejecutar programas ervlet Javas en cualquier equipo viejo. En primer lugar, usted tiene que instalar un programa especial llamado motor de servlets para convertir tu ordenador en un servidor que es capaz de ejecutar…