¿Cómo explicar los resultados de una clasificación r análisis predictivo modelo
Otra tarea de análisis predictivo es clasificar nuevos datos mediante la predicción de lo que la clase de un elemento de destino de los datos pertenece, dado un conjunto de variables independientes. Puede, por ejemplo, clasificar un cliente por tipo - por ejemplo, como un cliente de alto valor, cliente, o un cliente que está listo para cambiar a un competidor - mediante el uso de un árbol de decisión.
Para ver algo de información útil sobre el modelo R Clasificación, escriba el siguiente código:
> Resumen (modelo) Longitud Clase Mode1 BinaryTreeS4
los Clase columna que dice que usted ha creado un árbol de decisión. Para ver cómo se están determinando las divisiones, sólo tiene que escribir el nombre de la variable en la que asignó el modelo, en este caso modelo, Me gusta esto:
> ModelConditional árbol inferencia con 6 terminales nodesResponse: seedTypeInputs: área, perímetro, compacidad, longitud, anchura, asimetría, length2Number de observaciones: 1471) de área lt; = 16.2- criterio = 1, estadística =) Área 123.4232 lt; = 13.37- criterio = 1, estadística = 63.5493) longitud2 lt; = 4.914- criterio = 1, estadística = 22.2514) * pesos = 113) longitud2> 4,9145) * pesos = 452) Zona de> 13.376) longitud2 lt; = 5.396- criterio = 1, estadística = 16.317) * pesos = 336) longitud2> 5,3968) * pesos = 81) Zona de> 16,29) longitud2 lt; = 5.877- criterio = 0,979, estadística = 8.76410) * pesos = 109) longitud2> 5,87711) * pesos = 40
Aún mejor, se puede visualizar el modelo mediante la creación de una parcela del árbol de decisión con este código:> plot (modelo)
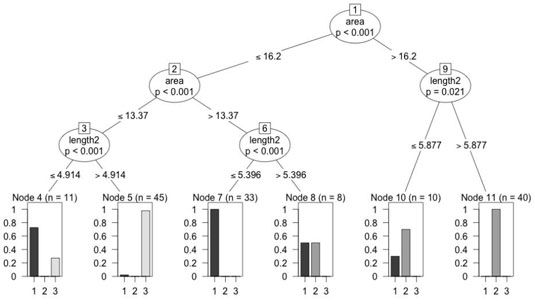
Esta es una representación gráfica de un árbol de decisión. Se puede ver que los imita en general de forma que de un árbol real. Está hecho de nodos (los círculos y rectángulos) y enlaces o bordes (las líneas de conexión).
El primer nodo (que comienza en la parte superior) se llama nodo raíz y los nodos en la parte inferior de los árboles (rectángulos) se llaman nodos terminales. Hay cinco nodos de decisión y seis nodos terminales.
En cada nodo, el modelo toma una decisión sobre la base de los criterios establecidos en el círculo y los enlaces, y elige un camino a seguir. Cuando el modelo alcanza un nodo terminal, un veredicto o se adopte una decisión final. En este caso particular, dos atributos, el y el, se utilizan para decidir si un tipo de semilla es dada en la clase 1, 2 o 3.
Por ejemplo, tomemos la observación # 2 del conjunto de datos. Cuenta con una de 4.956 y una de las 14.88. Usted puede utilizar el árbol que acaba de construir para decidir qué tipo particular de semilla de esta observación pertenece. Aquí está la secuencia de pasos:
Comience en el nodo raíz, que es el nodo 1 (el número se muestra en el pequeño cuadrado en la parte superior del círculo). Decidir basado en el atributo: ¿Es la de la observación # 2 inferior o igual a (denotado por lt; =) 16,2? La respuesta es sí, por lo que se mueve a lo largo de la ruta de acceso al nodo 2.
En el nodo 2, el modelo se pregunta: ¿Es la zona lt; = 13.37? La respuesta es no, a fin de tratar el siguiente enlace que pregunta: ¿Es la zona> 13.37? La respuesta es sí, por lo que se mueve a lo largo de la ruta de acceso al nodo 6. En este nodo del modelo de pregunta: ¿Es la longitud2 lt; = 5,396? Lo es, y que se mueve al nodo terminal 7 y el veredicto es que la observación # 2 es de las semillas de tipo 1. Y es, de hecho, las semillas de tipo 1.
El modelo hace que el proceso para todas las demás observaciones para predecir sus clases.
Para saber si usted entrenó un buen modelo, cotejarla con los datos de entrenamiento. Puede ver los resultados en una tabla con el siguiente código:
> Mesa (predecir (modelo), trainset $ seedType) 1 2 31 45 4 32 3 47 03 1 0 44
Los resultados muestran que el error (o tasa de errores de clasificación) es 11 de 147, o 7,48 por ciento.
Con los resultados calculados, el siguiente paso es leer la tabla.
Las predicciones correctas son las que muestran los números de columna y fila como el mismo. Esos resultados se muestran como una línea diagonal desde la parte superior izquierda a la parte inferior derecha; por ejemplo, [1,1], [2,2], [3,3] es el número de predicciones correctas de dicha categoría.
Así que para las semillas de tipo 1, el modelo predijo correctamente que 45 veces, mientras que la semilla clasificación errónea 7 veces (4 veces como semillas de tipo 2, y 3 veces más de tipo 3). Para las semillas de tipo 2, el modelo predijo correctamente que 47 veces, mientras que clasificar erróneamente 3 veces. Para las semillas de tipo 3, el modelo predijo correctamente que 44 veces, mientras que clasificar erróneamente que sólo una vez.
Esto demuestra que este es un buen modelo. Así que ahora a evaluar con los datos de prueba. Aquí está el código que utiliza los datos de prueba para predecir y almacenarlo en una variable (testPrediction) Para su uso posterior:
> TestPrediction lt; - predecir (modelo, newdata = testset)
Para evaluar cómo el modelo realizado con los datos de prueba, verlo en una mesa y calcular el error, para el cual el código es el siguiente:
> Mesa (testPrediction, testset $ seedType) testPrediction 2 31 23 1 2 12 1 19 03 1 0 17
Los resultados muestran que el error es de 5 64, o 7,81 por ciento. Esto es consistente con los datos de entrenamiento.
-
 Conceptos básicos de los modelos de clasificación de las predicciones analíticas
Conceptos básicos de los modelos de clasificación de las predicciones analíticas - Fundamentos de análisis predictivo de proceso de datos clasificaciones
- Cómo categorizar los modelos de análisis predictivo
- ¿Cómo crear una clasificación r análisis predictivo modelo
- Cómo crear un modelo de análisis predictivo con la regresión r
- Cómo ensemble métodos para aumentar la precisión de predicción analítica
Una vez que se crea un modelo de regresión R para el análisis predictivo, que desea ser capaz de explicar los resultados del análisis. Para ver algo de información útil sobre el modelo, el tipo en el siguiente código:> Resumen (modelo)La…
Después de desarrollar su modelo de análisis predictivo y con éxito; para ello, ya está listo para implementarlo en el entorno de producción. El objetivo final de un proyecto de análisis predictivo es poner el modelo se construye en el proceso…
El conjunto de datos se analizan para hacer una predicción sobre es el conjunto de datos Semillas, que se puede encontrar en la máquina de aprendizaje del repositorio UCI. Este conjunto de datos tiene 210 observaciones y 7 atributos, además de la…
Para hacer predicciones analíticas con nuevos datos, sólo tiene que utilizar la función con una lista de los siete valores de los atributos. El siguiente código hace ese trabajo:> NewPrediction lt; - predecir (modelo,
lista (cilindros =…
Con el fin de realizar un análisis predictivo, usted tiene que obtener los datos en una forma que el algoritmo puede utilizar para construir un modelo. Para hacer eso, usted tiene que tomar un poco de tiempo para entender los datos y conocer su…
Aprendizaje supervisado es una tarea de aprendizaje automático que aprende de los datos de análisis predictivo que ha sido etiquetados. Una manera de pensar sobre el aprendizaje supervisado es que el etiquetado de los datos se realiza bajo la…
Antes de que pueda alimentar el clasificador Apoyo Vector Machine (SVM) con los datos que se cargan durante el análisis predictivo, debe dividir el conjunto de datos completo en un conjunto de entrenamiento y de prueba.Afortunadamente, scikit-learn…
Al analizar la calidad de un modelo predictivo, usted querrá medir su precisión. El un pronóstico más preciso el modelo hace, más útil que es para la empresa, que es una indicación de su calidad. Todo esto es bueno - a excepción de cuando el…
LA árbol de decisión es un enfoque de análisis predictivo que puede ayudarle a tomar decisiones. Supongamos, por ejemplo, que tiene que decidir si invertir una cierta cantidad de dinero en uno de los tres proyectos empresariales: un negocio de…
En análisis supervisadas, tanto de entrada como de salida preferidos son parte de los datos de entrenamiento. El modelo de análisis predictivo se presenta con los resultados correctos como parte de su proceso de aprendizaje. Tal aprendizaje…
Visualización de los resultados de su análisis predictivo realmente ayuda a las partes interesadas a comprender los pasos a seguir. He aquí algunas maneras de utilizar técnicas de visualización para informar de los resultados de sus modelos a…
La minería de datos consiste en explorar y analizar grandes cantidades de datos para encontrar las pautas de los grandes datos. Las técnicas salieron de los campos de la estadística y la inteligencia artificial (IA), con un poco de gestión de…