Conceptos básicos de los cúmulos de datos en el análisis predictivo
LA conjunto de datos (o la recolección de datos) es un conjunto de elementos en el análisis predictivo. Por ejemplo, un conjunto de documentos es un conjunto de datos, donde los elementos de datos son documentos. Un conjunto de información social de los usuarios de la red (nombre, edad, lista de amigos, fotos, etc.) es un conjunto de datos, donde los elementos de datos son los perfiles de los usuarios de redes sociales.
Agrupamiento de datos es la tarea de dividir un conjunto de datos en subconjuntos de elementos similares. Los productos también pueden ser referidos como casos, la observación, entidades u objetos de datos. En la mayoría de los casos, un conjunto de datos se representa en forma de tabla - una matriz de datos. Una matriz de datos es una tabla de números, documentos, o expresiones, representados en filas y columnas como sigue:
Cada fila corresponde a un artículo dado en el conjunto de datos.
Las filas se denominan a veces artículos, objetos, instancias u observaciones.
Cada columna representa una característica particular de un elemento.
Las columnas se denominan características o atributos.
La aplicación de la agrupación de datos a un conjunto de datos genera grupos de elementos de datos similares. Estos grupos se denominan racimos - colecciones de elementos de datos similares.
Semejante artículos tienen una relación fuerte y medible entre ellos - las verduras frescas, por ejemplo, son más similares entre sí de lo que son a los alimentos congelados - y técnicas de agrupamiento usan esa relación para agrupar los elementos.
La fuerza de una relación entre dos o más artículos se puede cuantificar como una medida de similitud: Una función matemática calcula la correlación entre dos elementos de datos. Los resultados de ese cálculo, llamados valores de similitud, esencialmente comparar un elemento de datos en particular a todos los demás elementos en el conjunto de datos. Esos otros artículos estarán ya sea más similar o menos similar en comparación con ese elemento específico.
Similitudes calculadas desempeñan un papel importante en la asignación de artículos a los grupos (racimos). Cada grupo tiene un elemento que mejor representa IT este artículo se refiere como una representante del clúster.
Considere un conjunto de datos que consta de varios tipos de frutas en una canasta. La canasta tiene frutos de diferentes tipos, tales como manzanas, plátanos, limones y peras. En este caso, las frutas son los elementos de datos. El proceso de agrupamiento de datos extrae grupos de frutos similares fuera de este conjunto de datos (cesta de frutas diferentes).
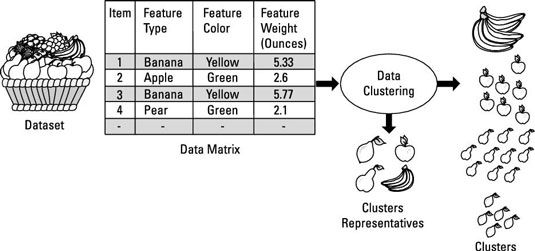
El primer paso en un proceso de agrupación de datos es traducir este conjunto de datos en una matriz de datos: Una forma de modelar este conjunto de datos es tener las filas representan los elementos en el conjunto de datos (frutas) - y las columnas representan las características o características, que describen Los artículos.
Por ejemplo, una característica de la fruta puede ser el tipo de fruta (tales como un plátano o manzana), peso, color, o el precio. En este ejemplo, el conjunto de datos, los artículos tienen tres características: Tipo de fruta, color y peso.
En la mayoría de los casos, la aplicación de una técnica de agrupación de datos para el conjunto de datos de frutas como el descrito anteriormente le permite
Recuperar grupos (clusters) de elementos similares. Se puede decir que su fruto es de N número de grupos. Después de eso, si tienes que elegir una fruta al azar, usted será capaz de hacer una declaración sobre ese tema como parte de uno de los grupos N.
Recuperar representantes del clúster de cada grupo. En este ejemplo, un representante de clúster sería escoger un tipo de fruta de la canasta y poner a un lado. Las características de esta fruta son tales que la fruta que mejor representa el grupo al que pertenece.
Cuando haya terminado la agrupación, el conjunto de datos se organiza y divide en agrupaciones naturales.
Agrupamiento de datos revela la estructura de los datos mediante la extracción de agrupaciones naturales de un conjunto de datos. Por lo tanto, el descubrimiento de grupos es un paso esencial hacia la formulación de ideas e hipótesis acerca de la estructura de los datos y la obtención de conocimientos para entender mejor.
Agrupamiento de datos también puede ser una forma de modelo de datos: Representa un cuerpo más grande de los datos por grupos o representantes de racimo.
Además, su análisis puede buscar simplemente para dividir los datos en grupos de elementos similares - como cuando segmentación de mercado particiones de datos de destino en el mercado en grupos tales como
Los consumidores que comparten los mismos intereses (como la cocina mediterránea)
Los consumidores que tienen necesidades comunes (por ejemplo, las personas con alergias a los alimentos específicos)
La identificación de los grupos de clientes similares puede ayudarle a desarrollar una estrategia de marketing que se ocupa de las necesidades de grupos específicos.
Por otra parte, la agrupación de datos también puede ayudar a identificar, aprender, o predecir la naturaleza de los nuevos elementos de datos - sobre todo cómo los nuevos datos pueden vincularse con hacer predicciones. Por ejemplo, en reconocimiento de patrones, el análisis de patrones en los datos (por ejemplo, los patrones de compra en determinadas regiones o grupos de edad) puede ayudarle a desarrollar el análisis predictivo - en este caso, la predicción de la naturaleza de los elementos de datos futuras que pueden encajar bien con los patrones establecidos.
El ejemplo cesta de frutas utiliza la agrupación de datos para distinguir entre diferentes elementos de datos. Suponga que su empresa ensambla cestas de fruta de encargo, y una nueva, fruto desconocido se introduce en el mercado. ¿Quieres aprender o predecir que agrupar el nuevo elemento pertenecerá a si lo añade a la cesta de frutas.
Debido a que usted ya ha aplicado la agrupación de datos para el conjunto de datos de la fruta, que tiene cuatro grupos - que hace que sea más fácil de predecir qué grupo (tipo específico de fruta) es apropiado para el nuevo elemento. Todo lo que tienes que hacer es comparar el fruto desconocido para los representantes de los otros cuatro clusters e identificar qué grupo es el mejor partido.
Aunque este proceso puede parecer obvio para una persona que trabaja con un pequeño conjunto de datos, no es tan evidente en una escala mayor - cuando tienes a agruparse millones de artículos sin examinar cada uno de ellos. La complejidad se vuelve exponencial cuando el conjunto de datos es grande, diversa y relativamente incoherente - que es por qué existen algoritmos de agrupamiento: Ordenadores hacer ese tipo de trabajo mejor.
-
 Son los elementos del conjunto de datos sin correlación?
Son los elementos del conjunto de datos sin correlación? -
") Análisis exploratorio de datos (eda)
Análisis exploratorio de datos (eda) -
 Cómo el análisis predictivo de apoyo de máquinas de vectores predice el futuro
Cómo el análisis predictivo de apoyo de máquinas de vectores predice el futuro - ¿Cómo elegir un algoritmo para un modelo de análisis predictivo
- Cómo agrupar por vecinos más cercanos en el análisis predictivo
- Cómo convertir los datos en bruto en una matriz de análisis predictivo
Después de que haya elegido su número de grupos de análisis predictivo y ha configurado el algoritmo para rellenar los racimos, usted tiene un modelo predictivo. Puedes hacer predicciones en base a nuevos datos entrantes llamando al predecir…
Cuando los datos están listos y ya está a punto de comenzar la construcción de su modelo predictivo para el análisis, es útil para delinear su metodología de pruebas y elaborar un plan de pruebas. La prueba debe ser impulsada por los objetivos…
Cuando haya definido los objetivos del modelo de análisis predictivo, el siguiente paso es identificar y preparar los datos que va a utilizar para construir su modelo. La secuencia general de pasos es la siguiente:Identificar las fuentes de…
K es una entrada al algoritmo de análisis- predictivo que representa el número de grupos que el algoritmo debe extraer de un conjunto de datos, expresada algebraicamente como k. Un algoritmo K-means divide un determinado conjunto de datos en k…
En análisis supervisadas, tanto de entrada como de salida preferidos son parte de los datos de entrenamiento. El modelo de análisis predictivo se presenta con los resultados correctos como parte de su proceso de aprendizaje. Tal aprendizaje…
Una herramienta de código abierto que es únicamente útil en el análisis predictivo es Apache Mahout. Esta biblioteca de aprendizaje de máquinas incluye versiones a gran escala de la agrupación, clasificación, filtrado colaborativo y otros…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original. Por lo tanto usted tiene que reducir el número de dimensiones mediante la aplicación de un algoritmo de reducción de…
Visualización de los resultados de su análisis predictivo realmente ayuda a las partes interesadas a comprender los pasos a seguir. He aquí algunas maneras de utilizar técnicas de visualización para informar de los resultados de sus modelos a…
La minería de datos consiste en explorar y analizar grandes cantidades de datos para encontrar las pautas de los grandes datos. Las técnicas salieron de los campos de la estadística y la inteligencia artificial (IA), con un poco de gestión de…
Una tabla dinámica en Excel le permite pasar menos tiempo el mantenimiento de sus cuadros de mando e informes y más tiempo haciendo otras cosas útiles. Sin utilidad en el conjunto de Excel le permite lograr este modelo de datos eficiente mejor…
El primer elemento de una ggplot2 capa es los datos. Sólo hay una regla en R para el suministro de datos para ggplot (): Sus datos deben estar en la forma de una trama de datos. Esto es diferente de gráficos de base, que permiten el trazado de los…
Datos - la información utilizada en las estadísticas - puede ser cualitativa o cuantitativa. Datos cualitativos divide un conjunto de datos (el conjunto de datos que haya reunido) en trozos discretos basado en un atributo específico. Por ejemplo,…