Cómo visualizar las agrupaciones en un k-significa modelo de aprendizaje no supervisado
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original. Por lo tanto usted tiene que reducir el número de dimensiones mediante la aplicación de un algoritmo de reducción de dimensionalidad que opera en los cuatro números y emite dos nuevos números (que representan los cuatro números originales) que puede utilizar para hacer la trama.
| Sépalo Longitud | Sépalo Ancho | Pétalo Longitud | Pétalo Ancho | Clase Objetivo / Label |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Setosa (0) |
| 7.0 | 3.2 | 4.7 | 1.4 | Versicolor (1) |
| 6.3 | 3.3 | 6.0 | 2.5 | Virginica (2) |
El siguiente código hará la reducción dimensión:
>>> From sklearn.decomposition PCA importación >>> from sklearn.datasets importar load_iris >>> iris = load_iris () >>> pca = PCA (n_components = 2) .fit (iris.data) >>> pca_2d = pca .transform (iris.data)
Las líneas 2 y 3 de carga del conjunto de datos del iris.
Después de ejecutar el código, puede escribir el pca_2d variable en el intérprete y se matrices de salida (pensar en una array como un contenedor de elementos en una lista) con dos elementos en lugar de cuatro. Ahora que tiene el conjunto de características reducido, puede trazar los resultados con el siguiente código:
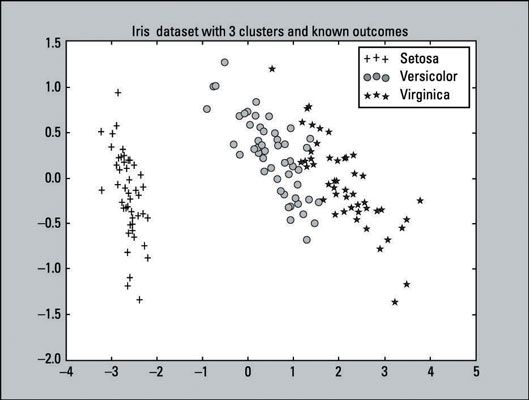
>>> Pylab importación como pl >>> for i in range (0, pca_2d.shape [0]): >>> si iris.target [i] == 0: >>> c1 = pl.scatter (pca_2d [ i, 0], pca_2d [i, 1], c = 'r', marcador = '+') >>> elif iris.target [i] == 1: >>> c2 = pl.scatter (pca_2d [i , 0], pca_2d [i, 1], c = 'g', marcador = 'o') >>> elif iris.target [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'b', marcador = '*') >>> pl.legend ([c1, c2, c3], ['Setosa', 'versicolor', 'Virginica'] ) >>> pl.title ('conjunto de datos Iris con 3 clusters y knownoutcomes') >>> pl.show ()La salida de este código es una trama que debe ser similar al siguiente gráfico. Este es un gráfico que representa cómo los resultados conocidos del conjunto de datos del iris debe ser similar. Es lo que le gustaría que la agrupación K-means para lograr.
La imagen muestra un gráfico de dispersión, que es un gráfico de los puntos trazados que representa una observación en un gráfico, de todas las 150 observaciones. Como se indica en las parcelas de gráfico y leyenda:
Hay 50 ventajas que representan la Setosa clase.
Hay 50 círculos que representan la Clase versicolor.
Hay 50 estrellas que representan la Clase Virginica.
El siguiente gráfico muestra una representación visual de los datos que usted está pidiendo K-means a agruparse: un gráfico de dispersión con 150 puntos de datos que no han sido etiquetados (por lo tanto todos los puntos de datos son del mismo color y forma). El K-means algoritmo no sabe cualquier objetivo resultados- los datos reales que estamos corriendo por el algoritmo no ha tenido su dimensionalidad reducida todavía.
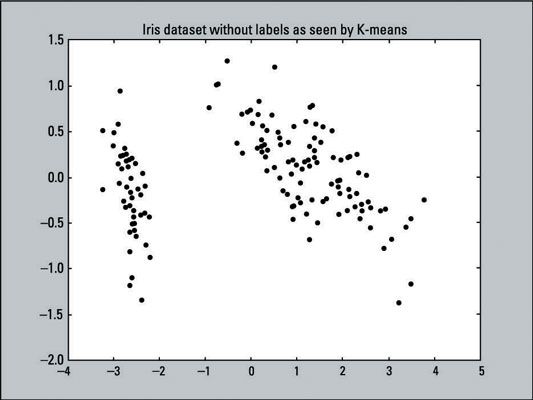
La siguiente línea de código crea este gráfico de dispersión, utilizando los valores X e Y de pca_2d y colorear todos los puntos de datos negro (c = 'negro' establece el color a negro).
>>> Pl.scatter (pca_2d [:, 0], pca_2d [:, 1], c = 'negro') >>> pl.show ()
Si intenta ajustar los datos en dos dimensiones, que se redujo en PCA, el K-means algoritmo dejará de agrupar las clases virginica y Versicolor correctamente. Utilizando PCA preprocesar los datos destruirán demasiada información que K-means necesidades.
Después de K-means ha instalado los datos del iris, se puede hacer un gráfico de dispersión de los grupos que el algoritmo produce- Simplemente ejecute el siguiente código:
>>> For i in range (0, pca_2d.shape [0]): >>> si kmeans.labels_ [i] == 1: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [ i, 1], c = 'r', marcador = '+') >>> elif kmeans.labels_ [i] == 0: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i , 1], c = 'g', marcador = 'o') >>> elif kmeans.labels_ [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'b', marcador = '*') >>> pl.legend ([c1, c2, c3], ['Grupo 1', 'Cluster 0', 'Grupo 2']) >>> pl.title ('K-significa cúmulos el conjunto de datos Iris en 3clusters') >>> pl.show ()Recordemos que K-means etiquetan las primeras 50 observaciones con la etiqueta de 1, el segundo 50 con la etiqueta de 0, y el último 50 con la etiqueta de 2. En el código que acabamos de dar, las líneas con el si, elif, y leyenda declaraciones (líneas 2, 5, 8, 11) refleja esas etiquetas. Este cambio se hizo para que sea fácil de comparar con los resultados reales.
La salida del diagrama de dispersión se muestra aquí:
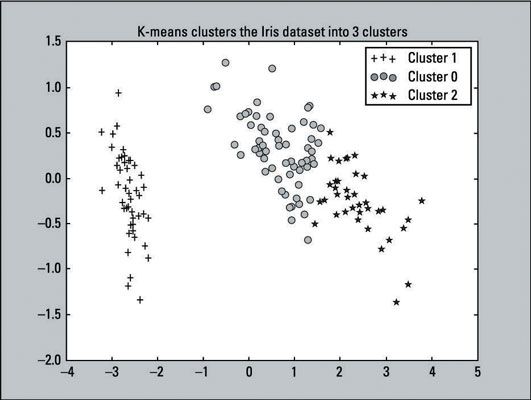
Comparar los K-means clustering de salida para el gráfico de dispersión original, - que proporciona las etiquetas porque los resultados son conocidos. Se puede ver que las dos parcelas se parecen entre sí. El algoritmo K-means hizo un muy buen trabajo con la agrupación. Aunque las predicciones no son perfectos, que se acercan. Eso es una victoria para el algoritmo.
En el aprendizaje no supervisado, que rara vez se consigue una salida que es 100 por ciento exacta porque los datos del mundo real rara vez es así de simple. Usted no sabrá cuántos grupos para elegir (o cualquier parámetro de inicialización para otros algoritmos de agrupamiento). Usted tendrá que manejar los valores extremos (puntos de datos que no parecen consistentes con otros) y conjuntos de datos complejos que son densos y no linealmente separables.
Sólo se puede llegar a este punto si sabe cuántos grupos del conjunto de datos tiene. Usted no necesita preocuparse de qué funciones le conviene usar o reducir la dimensionalidad de un conjunto de datos que tiene tan pocas características (en este caso, cuatro). Este ejemplo sólo reduce las dimensiones por el bien de la visualización de los datos en un gráfico. No encajaba el modelo con el conjunto de datos dimensionalidad reducida.
Aquí está la lista completa del código que crea dos gráficos de dispersión y códigos de color de los puntos de datos:
>>> From sklearn.decomposition importación PCA >>> from KMeans importación sklearn.cluster >>> from sklearn.datasets importar load_iris >>> pylab importación como pl >>> iris = load_iris () >>> pca = PCA (n_components = 2) .fit (iris.data) >>> pca_2d = pca.transform (iris.data) >>> pl.figure ('Referencia Parcela') >>> pl.scatter (pca_2d [:, 0], pca_2d [:, 1], c = iris.target) >>> KMeans = KMeans (n_clusters = 3, random_state = 111) >>> kmeans.fit (iris.data) >>> pl.figure ('K-means con 3 racimos ') >>> pl.scatter (pca_2d [:, 0], pca_2d [:, 1], c = kmeans.labels _) >>> pl.show ()-
 Fundamentos de k-medias y modelos de clustering DBSCAN para análisis predictivo
Fundamentos de k-medias y modelos de clustering DBSCAN para análisis predictivo - Cómo crear y ejecutar un modelo de aprendizaje no supervisado para hacer predicciones con k-medias
-
 Cómo crear un modelo de aprendizaje no supervisado con DBSCAN
Cómo crear un modelo de aprendizaje no supervisado con DBSCAN -
 Cómo crear un modelo de aprendizaje supervisado con regresión logística
Cómo crear un modelo de aprendizaje supervisado con regresión logística - ¿Cómo evaluar un modelo de aprendizaje no supervisado con k-medias
- Cómo cargar datos en un modelo de aprendizaje supervisado svm
Cuando usted está aprendiendo un nuevo lenguaje de programación, es costumbre escribir el " hola mundo " programa. Para el aprendizaje automático y análisis predictivo, la creación de un modelo para clasificar el conjunto de datos Iris es su "…
Aprendizaje supervisado es una tarea de aprendizaje automático que aprende de los datos de análisis predictivo que ha sido etiquetados. Una manera de pensar sobre el aprendizaje supervisado es que el etiquetado de los datos se realiza bajo la…
Antes de que pueda alimentar el clasificador Apoyo Vector Machine (SVM) con los datos que se cargan durante el análisis predictivo, debe dividir el conjunto de datos completo en un conjunto de entrenamiento y de prueba.Afortunadamente, scikit-learn…
Una herramienta de código abierto que es únicamente útil en el análisis predictivo es Apache Mahout. Esta biblioteca de aprendizaje de máquinas incluye versiones a gran escala de la agrupación, clasificación, filtrado colaborativo y otros…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original porque no se puede trazar las cuatro coordenadas (de las características) del conjunto de datos en una pantalla bidimensional.…
Después de crear el subconjunto apropiado de sus datos, el siguiente paso en el análisis es probable que sea para realizar algunos cálculos con R.Cómo hacer aritmética en columnas de una trama de datosR hace que sea muy fácil de realizar…
Una de las tareas que puede hacer con frecuencia en una hoja de cálculo que también se puede hacer en I es el cálculo de fila o columna de totales. La forma más sencilla de hacerlo es utilizar las funciones rowSums () y colSums ().Del mismo…
La cantidad en la que dos variables de datos varían juntos puede ser descrita por el coeficiente de correlación. En R, se obtiene la correlación entre un conjunto de variables muy fácilmente mediante el uso de la cor () función. Sólo tiene que…
Una aplicación muy útil de subconjuntos de datos es encontrar y eliminar valores duplicados. R tiene una función útil, duplicado (), que encuentra valores duplicados y devuelve un vector lógico que indica si el valor específico es un duplicado…
Ahora que ha revisado las reglas para la creación de subconjuntos, puede probar con algunas tramas de datos en R. Sólo tienes que recordar que una trama de datos es un objeto bidimensional y contiene filas, así como columnas. Esto significa que…
Estadísticos encanta cuando se puede vincular una variable de datos a otro. R puede ayudar a encontrar esta relación. Luz del sol, por ejemplo, es perjudicial para las faldas: Cuanto más tiempo el sol brilla, las faldas más cortas convertirse.…
Vectores, listas y cuadros de datos juegan un papel importante en la representación de datos en R, por lo que ser capaz de especificar de manera sucinta y correctamente un subconjunto de sus datos es importante.Hay tres operadores principales que…