Cómo visualizar el clasificador en un SVM aprendizaje supervisado modelo
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original porque no se puede trazar las cuatro coordenadas (de las características) del conjunto de datos en una pantalla bidimensional. Por lo tanto usted tiene que reducir las dimensiones mediante la aplicación de un reducción de dimensionalidad algoritmo para las características.
En este caso, el algoritmo que va a utilizar para hacer la transformación de datos (la reducción de las dimensiones de las características) se llama Análisis de Componentes Principales (PCA).
| Sépalo Longitud | Sépalo Ancho | Pétalo Longitud | Pétalo Ancho | Clase Objetivo / Label |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Setosa (0) |
| 7.0 | 3.2 | 4.7 | 1.4 | Versicolor (1) |
| 6.3 | 3.3 | 6.0 | 2.5 | Virginica (2) |
El algoritmo PCA toma las cuatro características (números), hace un poco de matemática en ellos, y emite dos nuevos números que usted puede utilizar para hacer la trama. Piense en PCA como siguiendo dos pasos generales:
Toma como entrada un conjunto de datos con muchas características.
Reduce dicha entrada a un conjunto más pequeño de características (definida por el usuario o un algoritmo determinado) mediante la transformación de los componentes del conjunto de características en lo que considera como los principales componentes (principal).
Esta transformación del conjunto de características también se llama extracción de características. El siguiente código hace la reducción dimensión:
>>> From sklearn.decomposition PCA importación >>> pca = PCA (n_components = 2) .fit (X_train) >>> pca_2d = pca.transform (X_train)
Si ya has importado ningún bibliotecas o bases de datos, no es necesario volver a importar o cargarlos en su sesión de Python actual. Si lo hace, sin embargo, no debería afectar a su programa.
Después de ejecutar el código, puede escribir el pca_2d variable en el intérprete y ver que da salida a las matrices con dos elementos en lugar de cuatro. Estos dos nuevos números son representaciones matemáticas de los cuatro números viejos. Cuando se establece la función reducida, puede trazar los resultados utilizando el siguiente código:
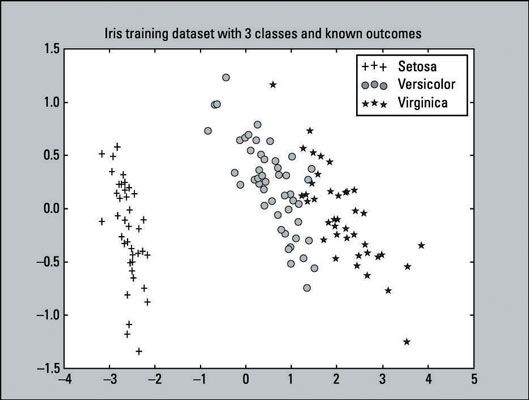
>>> Pylab importación como pl >>> for i in range (0, pca_2d.shape [0]): >>> si y_train [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c 'r' =, marcador = '+') >>> elif y_train [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', marcador = 'o') >>> elif y_train [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i , 1], c = 'b', marcador = '*') >>> pl.legend ([c1, c2, c3], ['Setosa', 'versicolor', 'Virginica']) >>> pl. título ('formación de datos del iris con 3 clases andknown resultados') >>> pl.show ()Esto es un gráfico de dispersión - una visualización de puntos trazados que representan observaciones en un gráfico. Este gráfico de dispersión particular, representa los resultados conocidos de la formación de datos Iris. Hay 135 puntos trazados (observaciones) de nuestro conjunto de datos de entrenamiento. El conjunto de datos de entrenamiento consiste en
45 ventajas que representan la clase Setosa.
48 círculos que representan la clase versicolor.
42 estrellas que representan la clase Virginica.
Puede confirmar el número indicado de clases mediante la introducción de código siguiente:
>>> Suma (y_train == 0) 45 >>> suma (y_train == 1) 48 >>> suma (y_train == 2) 42
De esta figura se puede decir claramente que la clase Setosa es linealmente separable de las otras dos clases. Mientras que las clases Versicolor y virginica no son completamente separables por una línea recta, no son la superposición por mucho. Desde una perspectiva visual simple, los clasificadores deben hacer bastante bien.
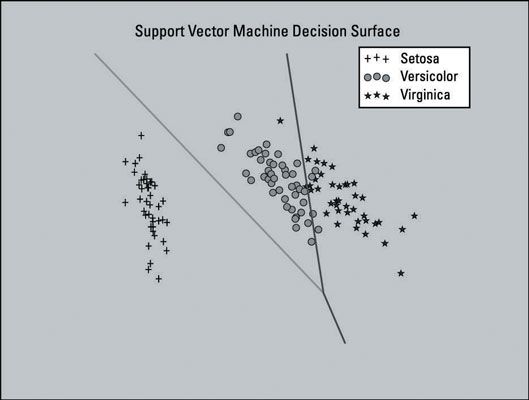
La siguiente imagen muestra un gráfico del modelo de Apoyo Vector Machine (SVM) entrenado con un conjunto de datos que se ha reducido a dos dimensiones características. Cuatro características es un pequeño ajuste característica en este caso, desea mantener los cuatro para que los datos pueden retener la mayor parte de su información útil. La trama se muestra aquí como una ayuda visual.
Esta parcela incluye la superficie decisión para el clasificador - el área en el gráfico que representa la función de decisión que utiliza SVM para determinar el resultado de la nueva entrada de datos. Las líneas se separan las áreas donde el modelo será predecir la clase particular que un punto de datos pertenece.
La sección izquierda de la parcela será predecir la clase Setosa, la sección media predecirá la clase versicolor, y la sección de la derecha va a predecir la clase Virginica.
El modelo SVM que creó no usaba el conjunto de funciones dimensionalmente reducida. Este modelo sólo utiliza la reducción de dimensionalidad aquí para generar una parcela de la superficie decisión del modelo de SVM - como ayuda visual.
La lista completa del código que crea la trama se proporciona como referencia. No se debe ejecutar en secuencia con nuestro ejemplo actual si usted está siguiendo a lo largo de. Puede sobrescribir algunas de las variables que ya pueda tener en la sesión.
El código para producir esta trama se basa en el código de ejemplo proporcionado en la scikit aprender sitio web. Usted puede aprender más sobre la creación de parcelas como estos en el scikit-learn sitio web.
Aquí está la lista completa del código que crea el terreno:
>>> Del PCA sklearn.decomposition importación >>> from sklearn.datasets importar load_iris >>> from sklearn svm importación >>> from sklearn cross_validation importación >>> pylab importación como pl >>> numpy importación como np >>> iris = load_iris () >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> pca = PCA (n_components = 2) .fit (X_train ) >>> pca_2d = pca.transform (X_train) >>> svmClassifier_2d = svm.LinearSVC (random_state = 111) .fit (pca_2d, y_train) >>> for i in range (0, pca_2d.shape [0]): >>> si y_train [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'r', s = 50, marcador = '+' ) >>> elif y_train [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', s = 50, marcador = 'o ') >>> elif y_train [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c =' b ', s = 50, marcador =' * ') >>> pl.legend ([c1, c2, c3], [' Setosa ',' versicolor ',' Virginica ']) >>> mín_x, máx_x = pca_2d [:, 0] .min () - 1, pca_2d [:, 0] .max () + 1 >>> mín_y, máx_y = pca_2d [:, 1] .min () - 1, pca_2d [:, 1] .max () + 1 >>> xx , yy = np.meshgrid (np.arange (mín_x, máx_x, 0.01), np.arange (mín_y, máx_y, 0.01)) >>> Z = svmClassifier_2d.predict (np.c_ [xx.ravel (), yy.ravel ()]) >>> Z = Z.reshape (xx.shape) >>> pl.contour (xx, yy, Z) >>> pl.title («Apoyo Vector Machine Decisión Surface ') >> > pl.axis ("off") >>> pl.show ()-
 Hadoop Sqoop para grandes datos
Hadoop Sqoop para grandes datos - Conceptos básicos de los modelos de clasificación de las predicciones analíticas
-
 Cómo el análisis predictivo de apoyo de máquinas de vectores predice el futuro
Cómo el análisis predictivo de apoyo de máquinas de vectores predice el futuro - Cómo crear y ejecutar un modelo de aprendizaje no supervisado para hacer predicciones con k-medias
- ¿Cómo crear una clasificación r análisis predictivo modelo
-
 Cómo crear un modelo de aprendizaje no supervisado con DBSCAN
Cómo crear un modelo de aprendizaje no supervisado con DBSCAN
Después de construir su primer modelo predictivo clasificación para el análisis de los datos, la creación de más modelos como que es una tarea muy sencilla en scikit. La única diferencia real de un modelo a otro es que puede que tenga que…
Después de que haya elegido su número de grupos de análisis predictivo y ha configurado el algoritmo para rellenar los racimos, usted tiene un modelo predictivo. Puedes hacer predicciones en base a nuevos datos entrantes llamando al predecir…
Otra tarea de análisis predictivo es clasificar nuevos datos mediante la predicción de lo que la clase de un elemento de destino de los datos pertenece, dado un conjunto de variables independientes. Puede, por ejemplo, clasificar un cliente por…
Para el análisis predictivo, es necesario cargar los datos para sus algoritmos a utilizar. Cargando el conjunto de datos Iris en scikit es tan simple como la emisión de un par de líneas de código, porque scikit ya ha creado una función para…
Cuando usted está aprendiendo un nuevo lenguaje de programación, es costumbre escribir el " hola mundo " programa. Para el aprendizaje automático y análisis predictivo, la creación de un modelo para clasificar el conjunto de datos Iris es su "…
Aprendizaje supervisado es una tarea de aprendizaje automático que aprende de los datos de análisis predictivo que ha sido etiquetados. Una manera de pensar sobre el aprendizaje supervisado es que el etiquetado de los datos se realiza bajo la…
Antes de que pueda alimentar el clasificador Apoyo Vector Machine (SVM) con los datos que se cargan durante el análisis predictivo, debe dividir el conjunto de datos completo en un conjunto de entrenamiento y de prueba.Afortunadamente, scikit-learn…
En análisis supervisadas, tanto de entrada como de salida preferidos son parte de los datos de entrenamiento. El modelo de análisis predictivo se presenta con los resultados correctos como parte de su proceso de aprendizaje. Tal aprendizaje…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original. Por lo tanto usted tiene que reducir el número de dimensiones mediante la aplicación de un algoritmo de reducción de…
Parece como si todo el mundo está utilizando Twitter para que sus sentimientos conocidos hoy. Por supuesto, el problema es que nadie sabe realmente el carácter común de esos sentimientos - es decir, si alguien pudiera derivar algún tipo de…
Ahora que ha revisado las reglas para la creación de subconjuntos, puede probar con algunas tramas de datos en R. Sólo tienes que recordar que una trama de datos es un objeto bidimensional y contiene filas, así como columnas. Esto significa que…
Estadísticos encanta cuando se puede vincular una variable de datos a otro. R puede ayudar a encontrar esta relación. Luz del sol, por ejemplo, es perjudicial para las faldas: Cuanto más tiempo el sol brilla, las faldas más cortas convertirse.…