Cómo crear un modelo de aprendizaje supervisado con regresión logística
Después de construir su primer modelo predictivo clasificación para el análisis de los datos, la creación de más modelos como que es una tarea muy sencilla en scikit
Conteúdo
Cómo cargar sus datos
Este listado de código cargará la iris conjunto de datos en su sesión:
>>> From sklearn.datasets importar load_iris >>> iris = load_iris ()
¿Cómo crear una instancia del clasificador
Las dos líneas de código siguientes crean una instancia del clasificador. La primera línea importa la biblioteca de regresión logística. La segunda línea crea una instancia del algoritmo de regresión logística.
>>> From sklearn linear_model importación >>> logClassifier = linear_model.LogisticRegression (C = 1, random_state = 111)
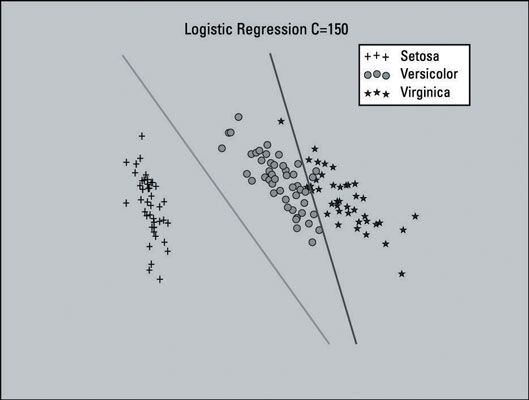
Observe el parámetro (parámetro de regularización) en el constructor. los parámetro de regularización se utiliza para evitar overfitting. El parámetro no es estrictamente necesario (el constructor va a funcionar bien sin él, ya que será por defecto C = 1). Creación de un clasificador de regresión logística utilizando C = 150 crea una mejor parcela de la superficie decisión. Usted puede ver las dos parcelas de abajo.
Cómo ejecutar los datos de entrenamiento
Usted tendrá que dividir el conjunto de datos en capacitación y de prueba antes de poder crear una instancia del clasificador de regresión logística. El siguiente código realizar esa tarea:
>>> From sklearn cross_validation importación >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> logClassifier.fit (X_train, y_train)
Línea 1 importa la biblioteca que permite dividir el conjunto de datos en dos partes.Línea 2 llama a la función de la biblioteca que se divide el conjunto de datos en dos partes y asigna los conjuntos de datos ahora divididas en dos pares de variables.Línea 3 toma la instancia del clasificador de regresión logística que acaba de crear y llama al ajuste método para entrenar el modelo con la formación de datos.
Cómo visualizar el clasificador
En cuanto a la superficie decisión sobre la trama, parece que algunos ajustes que hay que hacer. Si se mira cerca de la mitad de la parcela, se puede ver que muchos de los puntos de datos que pertenecen a la zona media (versicolor) están mintiendo en el área a la derecha (Virginica).
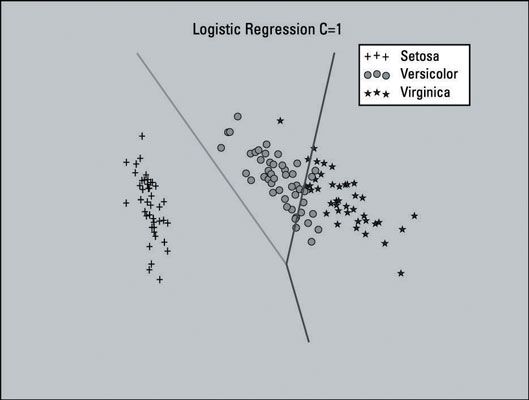
Esta imagen muestra la superficie de la decisión con un valor C de 150. Se ve visualmente mejor, así que la elección de utilizar este ajuste para el modelo de regresión logística parece apropiado.
Cómo ejecutar los datos de prueba
En el siguiente código, la primera línea alimenta el conjunto de datos de prueba para el modelo y la tercera línea muestra la salida:
>>> Predicho = logClassifier.predict (X_test) >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2])
¿Cómo evaluar el modelo
Puede Referencia cruzada la salida de la predicción en contra de la y_test array. Como resultado, se puede ver que predijo todos los puntos de datos de prueba correctamente. Aquí está el código:
>>> From métricas de importación sklearn >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray ([ 0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score (y_test, predicho) 1.0 # 1.0 es 100 por ciento de precisión> >> predicho == y_testarray ([Real, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype = bool)
Entonces, ¿cómo el modelo de regresión logística con parámetro C = 150 comparar a eso? Bueno, no se puede superar el 100 por ciento. Este es el código para crear y evaluar el clasificador logística con C = 150:
>>> LogClassifier_2 = linear_model.LogisticRegression (C = 150, random_state = 111) >>> logClassifier_2.fit (X_train, y_train) >>> predicho = logClassifier_2.predict (X_test) >>> metrics.accuracy_score (y_test, predicho) 0.93333333333333335 >>> metrics.confusion_matrix (y_test, predijo) matriz ([[5, 0, 0], [0, 2, 0], [0, 1, 7]])
Nos esperábamos algo mejor, pero en realidad fue peor. Hubo un error en las predicciones. El resultado es el mismo que el del modelo de apoyo Vector Machine (SVM).
Aquí está la lista completa del código para crear y evaluar un modelo de clasificación de regresión logística con los parámetros por defecto:
>>> From sklearn.datasets importar load_iris >>> from sklearn linear_model importación >>> from sklearn cross_validation importación >>> from métricas importación sklearn >>> iris = load_iris () >>> X_train, X_test, y_train, y_test = cross_validation .train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> logClassifier = linear_model.LogisticRegression (, random_state = 111) >>> logClassifier.fit (X_train, y_train) >>> predijo = logClassifier .predict (X_test) >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score (y_test, predicho) 1.0 # 1.0 es 100 por ciento de exactitud >>> predicho == y_testarray ([Real, True, True, True, True, True, True, True, True, True, True, True, True, True, True], dtype = bool)
-
 Conceptos básicos de los modelos de clasificación de las predicciones analíticas
Conceptos básicos de los modelos de clasificación de las predicciones analíticas - Conceptos básicos de las variables en la programación r para análisis predictivo
- Cómo crear y ejecutar un modelo de aprendizaje no supervisado para hacer predicciones con k-medias
-
 Cómo crear un modelo de aprendizaje no supervisado con DBSCAN
Cómo crear un modelo de aprendizaje no supervisado con DBSCAN - ¿Cómo explicar los resultados de los análisis predictivos de regresión r
-
 Cómo introducir los datos de la r de regresión para el análisis predictivo
Cómo introducir los datos de la r de regresión para el análisis predictivo
Para el análisis predictivo, es necesario cargar los datos para sus algoritmos a utilizar. Cargando el conjunto de datos Iris en scikit es tan simple como la emisión de un par de líneas de código, porque scikit ya ha creado una función para…
Para hacer predicciones analíticas con nuevos datos, sólo tiene que utilizar la función con una lista de los siete valores de los atributos. El siguiente código hace ese trabajo:> NewPrediction lt; - predecir (modelo,
lista (cilindros =…
Usted tiene que obtener los datos en una forma que el algoritmo puede utilizar para construir un modelo de análisis predictivo. Para ello, usted tiene que tomar un poco de tiempo para entender los datos y conocer la estructura de los datos. Llene…
Aprendizaje supervisado es una tarea de aprendizaje automático que aprende de los datos de análisis predictivo que ha sido etiquetados. Una manera de pensar sobre el aprendizaje supervisado es que el etiquetado de los datos se realiza bajo la…
Antes de que pueda alimentar el clasificador Apoyo Vector Machine (SVM) con los datos que se cargan durante el análisis predictivo, debe dividir el conjunto de datos completo en un conjunto de entrenamiento y de prueba.Afortunadamente, scikit-learn…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original porque no se puede trazar las cuatro coordenadas (de las características) del conjunto de datos en una pantalla bidimensional.…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original. Por lo tanto usted tiene que reducir el número de dimensiones mediante la aplicación de un algoritmo de reducción de…
Excel 2010 utiliza siete funciones lógicas - Y, FALSOS, SI, SI.ERROR, NOT, OR y TRUE - que aparecen en el menú desplegable del botón de comando lógico en la ficha Fórmulas de la cinta de opciones. Todas las funciones lógicas devuelven FALSE…
Parece como si todo el mundo está utilizando Twitter para que sus sentimientos conocidos hoy. Por supuesto, el problema es que nadie sabe realmente el carácter común de esos sentimientos - es decir, si alguien pudiera derivar algún tipo de…
Por suerte, R puede hacer frente a anomalías de los datos que confunden algunas otras plataformas estadísticos. Por ejemplo, en algunos casos, usted no tiene valores reales para calcular con. En la mayoría de los conjuntos de datos de la vida…
Como cualquier lenguaje de programación, R hace que sea fácil de compilar listas de datos ordenados y ordenados. Para encontrar subcadenas, puede utilizar la grep () función, que toma dos argumentos esenciales:patrón: El patrón que desea…
Los estadísticos a menudo tienen que tomar muestras de datos y luego calcular las estadísticas. Tomando una muestra es fácil con R, porque una muestra es realmente nada más que un subconjunto de datos. Para ello, se hace uso de muestra (), que…