Cómo crear un modelo de aprendizaje no supervisado con DBSCAN
DBSCAN (Densidad-Basado agrupación espacial de aplicaciones con ruido) es un algoritmo de agrupamiento popular utilizado como una alternativa a K-medias en el análisis predictivo. No requiere que se introduzca el número de grupos con el fin de ejecutar. Pero a cambio, tienes que sintonizar otros dos parámetros.
Conteúdo
La implementación scikit-learn proporciona un valor predeterminado para las EPS y parámetros min_samples, pero estás en general espera que para sintonizar esos. El parámetro eps es la distancia máxima entre dos puntos de datos a considerar en el mismo barrio. El parámetro min_samples es la cantidad mínima de puntos de datos en un barrio para ser considerado un clúster.
Una de las ventajas que tiene sobre DBSCAN K-means es que DBSCAN no se limita a un número determinado de grupos durante la inicialización. El algoritmo determinará un número de grupos sobre la base de la densidad de una región.
Tenga en cuenta, sin embargo, que el algoritmo depende de las EPS y parámetros min_samples de averiguar lo que debe ser la densidad de cada clúster. La idea es que estos dos parámetros son mucho más fáciles de elegir por algunos problemas de agrupamiento.
En la práctica, debe probar con varios algoritmos de agrupación.
Debido a que el algoritmo de DBSCAN tiene un concepto integrado de ruido, se utiliza comúnmente para detectar valores atípicos en los datos - por ejemplo, las actividades fraudulentas en las tarjetas de crédito, el comercio electrónico, o las reclamaciones de seguros.
Cómo ejecutar el conjunto de datos completo
Usted tendrá que cargar el conjunto de datos del iris en su sesión de Python. Aquí está el procedimiento:
Abra una nueva sesión de shell interactivo de Python.
Utilice una nueva sesión de Python para que la memoria es clara y tiene un borrón y cuenta nueva para trabajar.
Pegue el código siguiente en el símbolo del sistema y observar la salida:
>>> From sklearn.datasets importar load_iris >>> iris = load_iris ()
Después de ejecutar esas dos declaraciones, no debería ver los mensajes de la intérprete. El iris variables deben contener todos los datos del archivo iris.csv.
Crear una instancia de DBSCAN. Escriba el siguiente código en el intérprete:
>>> From sklearn.cluster importación DBSCAN >>> DBSCAN = DBSCAN (random_state = 111)
La primera línea de código importa la biblioteca DBSCAN en la sesión para que usted utilice. La segunda línea crea una instancia de DBSCAN con los valores por defecto de eps y min_samples.
Compruebe qué parámetros se utilizaron escribiendo el siguiente código en el intérprete:
>>> DbscanDBSCAN (eps = 0,5, = métricas "euclidiana", min_samples = 5, random_state = 111)
Coloque los datos del iris en el algoritmo de agrupamiento DBSCAN escribiendo el siguiente código en el intérprete:
>>> Dbscan.fit (iris.data)
Para comprobar los resultados, escriba el código siguiente en el intérprete:
>>> Dbscan.labels_array ([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0. , 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -1., 0., 0., 0., 0., 0., 0., 0., 0., 1, 1., 1., 1., 1., 1., 1., -1, 1., 1, -.... 1, 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1 ., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., 1., 1., 1., -1., 1., 1 ., 1., 1., -1., 1., 1., 1., 1., 1., 1., -1., -1., 1., -1., -1., 1 ., 1., 1., 1., 1., 1., 1., -1., -1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., -1., -1., 1., 1., 1., 1., 1., 1. , 1., 1., 1., 1., 1., 1., 1., 1.])
Si usted mira muy de cerca, verás que DBSCAN produjo tres grupos (-1, 0 y 1).
Cómo visualizar las agrupaciones
Vamos a conseguir un gráfico de dispersión de la salida DBSCAN. Escriba el siguiente código:
>>> From sklearn.decomposition PCA importación >>> pca = PCA (n_components = 2) .fit (iris.data) >>> pca_2d = pca.transform (iris.data) >>> for i in range (0, pca_2d.shape [0]): >>> si dbscan.labels_ [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c 'r' = , marcador = '+') >>> elif dbscan.labels_ [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', marcador = 'o') >>> elif dbscan.labels_ [i] == -1: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'b', marcador = '*') >>> pl.legend ([c1, c2, c3], ['Grupo 1', 'Grupo 2', 'Ruido']) >>> pl.title ('DBSCAN encuentra 2 grupos y ruido) >>> pl.show ()Aquí está el gráfico de dispersión que es la salida de este código:
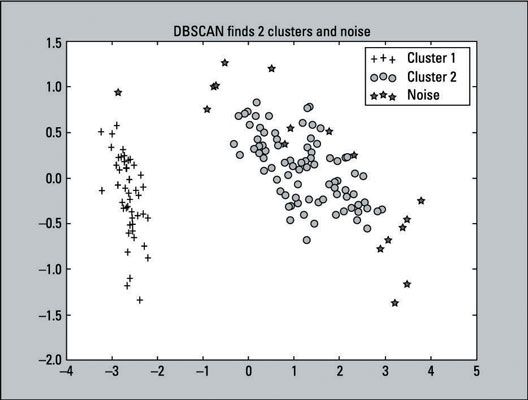
Se puede ver que DBSCAN produjo tres grupos. Tenga en cuenta, sin embargo, que la cifra se asemeja mucho a una solución de dos clúster: Muestra sólo 17 casos de etiqueta - 1. Eso es porque es una de dos clúster Solución del tercer grupo (-1) es ruido (outliers). Puede aumentar el parámetro de distancia (EPS) de la configuración predeterminada de 0,5 a 0,9, y se convertirá en una solución de dos clúster, sin ruido.
El parámetro de distancia es la distancia máxima es una observación más cercana al clúster. Cuanto mayor es el valor para el parámetro de distancia, menos racimos se encuentran ya grupos finalmente se funden en otros grupos. Las etiquetas -1 se encuentran diseminados por Grupo 1 y Grupo 2 en un par de lugares:
Cerca de los bordes de Cluster 2 (clases Versicolor y virginica)
Cerca del centro de Cluster 2 (clases Versicolor y virginica)
El gráfico sólo muestra una representación bidimensional de los datos. La distancia también se puede medir en dimensiones más altas.
Un caso anterior Grupo 1 (la clase Setosa)
¿Cómo evaluar el modelo
En este ejemplo, DBSCAN no produjo el resultado ideal, con los parámetros por defecto para el conjunto de datos del iris. Su actuación fue bastante consistente con otros algoritmos de agrupamiento que terminan con una solución de dos clúster.
El conjunto de datos del iris no se aprovecha de las funciones más potentes de DBSCAN - detección de ruido y la capacidad para descubrir grupos de formas arbitrarias. Sin embargo, DBSCAN es un algoritmo de agrupamiento muy popular y la investigación todavía se está trabajando en la mejora de su rendimiento.
-
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación -
 Conceptos básicos de los modelos de clasificación de las predicciones analíticas
Conceptos básicos de los modelos de clasificación de las predicciones analíticas -
 Conceptos básicos de los cúmulos de datos en el análisis predictivo
Conceptos básicos de los cúmulos de datos en el análisis predictivo - Fundamentos de k-medias y modelos de clustering DBSCAN para análisis predictivo
- Cómo agrupar por vecinos más cercanos en el análisis predictivo
- Cómo crear y ejecutar un modelo de aprendizaje no supervisado para hacer predicciones con k-medias
Después de construir su primer modelo predictivo clasificación para el análisis de los datos, la creación de más modelos como que es una tarea muy sencilla en scikit. La única diferencia real de un modelo a otro es que puede que tenga que…
Después de que haya elegido su número de grupos de análisis predictivo y ha configurado el algoritmo para rellenar los racimos, usted tiene un modelo predictivo. Puedes hacer predicciones en base a nuevos datos entrantes llamando al predecir…
Para el análisis predictivo, es necesario cargar los datos para sus algoritmos a utilizar. Cargando el conjunto de datos Iris en scikit es tan simple como la emisión de un par de líneas de código, porque scikit ya ha creado una función para…
Cuando usted está aprendiendo un nuevo lenguaje de programación, es costumbre escribir el " hola mundo " programa. Para el aprendizaje automático y análisis predictivo, la creación de un modelo para clasificar el conjunto de datos Iris es su "…
Aprendizaje supervisado es una tarea de aprendizaje automático que aprende de los datos de análisis predictivo que ha sido etiquetados. Una manera de pensar sobre el aprendizaje supervisado es que el etiquetado de los datos se realiza bajo la…
Antes de que pueda alimentar el clasificador Apoyo Vector Machine (SVM) con los datos que se cargan durante el análisis predictivo, debe dividir el conjunto de datos completo en un conjunto de entrenamiento y de prueba.Afortunadamente, scikit-learn…
K es una entrada al algoritmo de análisis- predictivo que representa el número de grupos que el algoritmo debe extraer de un conjunto de datos, expresada algebraicamente como k. Un algoritmo K-means divide un determinado conjunto de datos en k…
Una herramienta de código abierto que es únicamente útil en el análisis predictivo es Apache Mahout. Esta biblioteca de aprendizaje de máquinas incluye versiones a gran escala de la agrupación, clasificación, filtrado colaborativo y otros…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original porque no se puede trazar las cuatro coordenadas (de las características) del conjunto de datos en una pantalla bidimensional.…
El conjunto de datos del iris no es fácil representar gráficamente para el análisis predictivo en su forma original. Por lo tanto usted tiene que reducir el número de dimensiones mediante la aplicación de un algoritmo de reducción de…
Visualización de los resultados de su análisis predictivo realmente ayuda a las partes interesadas a comprender los pasos a seguir. He aquí algunas maneras de utilizar técnicas de visualización para informar de los resultados de sus modelos a…
La cantidad en la que dos variables de datos varían juntos puede ser descrita por el coeficiente de correlación. En R, se obtiene la correlación entre un conjunto de variables muy fácilmente mediante el uso de la cor () función. Sólo tiene que…