¿Cómo encontrar valor en su análisis de datos predictivo
Cualquier viaje exitoso requiere preparación seria. Modelos de análisis predictivo son esencialmente una inmersión profunda en grandes cantidades de datos. Si los datos no está bien preparada, el modelo de análisis predictivo saldrá de la inmersión sin peces. La clave para encontrar valor en el análisis predictivo es preparar a los datos - a fondo y meticuloso - que su modelo usará para hacer predicciones.
Conteúdo
Procesamiento de datos de antemano puede ser un obstáculo en el proceso de análisis predictivo. Ganar experiencia en la construcción de modelos de predicción - y, en particular, la preparación de datos - enseña la importancia de la paciencia. Selección, procesamiento, limpieza y preparación de los datos es laborioso. Es la tarea que más tiempo consume en el análisis predictivo del ciclo de vida. Sin embargo, adecuada y sistemática la preparación de los datos aumentará significativamente la probabilidad de que sus análisis de datos darán fruto.
Aunque lleva tiempo y esfuerzo para construir el primer modelo predictivo, una vez que tome el primer paso - la construcción del primer modelo que encuentra valor en sus datos - a continuación, los futuros modelos serán menos intensivos en recursos y requiere mucho tiempo, incluso con completamente nuevo conjuntos de datos. Incluso si usted no utiliza los mismos datos para el próximo modelo, sus analistas de datos se han adquirido una valiosa experiencia con el primer modelo.
Cómo profundizar en el análisis de datos de predicción
Usando una analogía fruta, que no sólo tiene que quitar el mal pelado o la cubierta, pero cavar en él para llegar al núcleo-medida que se acerca al núcleo, se llega a la mejor parte de la fruta. La misma regla se aplica a los grandes datos.
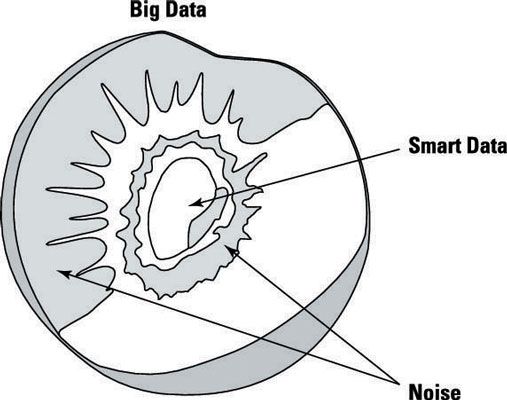
Fundamentos de la validez de los datos de análisis predictivo
Los datos no siempre es válida la primera vez que encuentras la misma. La mayoría de los datos es cualquiera incompleto (faltan algunos atributos o valores) o ruidoso (que contienen valores extremos o errores). En los campos de bioinformática biomédicos, por ejemplo, los valores extremos pueden conducir los análisis para generar resultados incorrectos o engañosos.
Los valores atípicos en los datos de cáncer, por ejemplo, pueden ser un factor importante que sesga la exactitud de los tratamientos médicos: muestras de expresión de genes pueden aparecer como falsos positivos de cáncer, ya que se analizaron frente a una muestra que contenía errores.
Datos inconsistentes son datos que contiene discrepancias en los atributos de datos. Por ejemplo, un registro de datos puede tener dos atributos que no coinciden: dicen, un código postal (por ejemplo, 20037) y un estado correspondiente (Delaware). Datos no válidos pueden dar lugar a modelos de predicción equivocada, lo que conduce a resultados analíticos engañosas que hará que las decisiones ejecutivas malos.
Por ejemplo, el envío de cupones para los pañales a las personas que no tienen hijos, es un error bastante obvio. Pero puede suceder fácilmente si el departamento de marketing de una empresa de pañales termina con resultados válidos de su modelo de análisis predictivo.
Gmail no siempre puede sugerir a la gente adecuada si usted está tratando de llenar los clientes potenciales que pudo haber olvidado incluir en una lista de correo electrónico de grupo. Facebook, para dar otro ejemplo, puede sugerir amigos que podrían no ser del tipo que usted está buscando.
En tales casos, es posible que haya demasiado grande un margen de error en los modelos o algoritmos. En la mayoría de los casos, los defectos y anomalías están en los datos seleccionados inicialmente para alimentar el modelo predictivo - pero los algoritmos que alimentar el modelo predictivo podría tener grandes trozos de datos no válidos.
Fundamentos de la variedad de datos en el análisis predictivo
La ausencia de uniformidad en los datos es otro gran reto conocido como variedad de datos. A partir de la corriente sin fin de datos no estructurados de texto (generados a través de correos electrónicos, presentaciones, informes de proyectos, textos, tweets) a los estados estructurados bancarios, datos de geolocalización y demografía de los clientes, las empresas están muriendo de hambre para esta variedad de datos.
La agregación de estos datos y su preparación para el análisis es una tarea compleja. ¿Cómo se puede integrar los datos generados a partir de diferentes sistemas como Twitter, Opentable.com, búsqueda de Google, y un tercero que registra datos de los clientes? Bueno, la respuesta es que no hay una solución común. Cada situación es diferente, y el científico de datos por lo general tiene que hacer muchas maniobras para integrar los datos y prepararlo para el análisis.
Aun así, un enfoque sencillo a la normalización puede apoyar la integración de datos de diferentes fuentes: Usted está de acuerdo con los proveedores de sus datos a un formato de datos estándar que su sistema puede manejar - un marco que puede hacer todas sus fuentes de datos generan datos que se puede leer por los seres humanos y máquinas. Piense en ello como un nuevo lenguaje que todas las fuentes de datos grande hablarán cada vez que están en el mundo de los grandes datos.
-
 Fundamentos de la estática y los datos se transmiten en analyics predictivos
Fundamentos de la estática y los datos se transmiten en analyics predictivos - La construcción de un modelo de análisis predictivo
- Fuentes de datos para proyectos de análisis predictivo
- Asegurar el éxito cuando se utiliza el análisis predictivo
- ¿Cómo se utilizan el análisis predictivo para tomar decisiones informadas
- ¿Cómo elegir un algoritmo para un modelo de análisis predictivo
La decisión de incluir valores atípicos en el análisis - o excluirlos - tendrá implicaciones para su modelo de análisis predictivo. Mantener los valores atípicos como parte de los datos de su análisis puede conducir a un modelo que no es…
Después de que se recogió inicialmente, los datos son por lo general en una dispersado estados reside en múltiples sistemas o bases de datos y debe ser analizada antes de la predicción de nada. Antes de que pueda utilizarlo para un modelo de…
Después de desarrollar su modelo de análisis predictivo y con éxito; para ello, ya está listo para implementarlo en el entorno de producción. El objetivo final de un proyecto de análisis predictivo es poner el modelo se construye en el proceso…
Para su proyecto de análisis predictivo, que necesitará para identificar fuentes apropiadas de datos, agrupar los datos de esas fuentes, y lo puso en un formato estructurado, bien organizado. Estas tareas pueden ser muy difícil y probablemente…
Después de la etapa de carga de extraer, transformar, cargar, después de obtener sus datos en esa base de datos separada, data mart, o almacén para el análisis, usted necesita para mantener los datos frescos por lo que los modeladores pueden…
Para hacer predicciones analíticas con nuevos datos, sólo tiene que utilizar la función con una lista de los siete valores de los atributos. El siguiente código hace ese trabajo:> NewPrediction lt; - predecir (modelo,
lista (cilindros =…
Cuando los datos están listos y ya está a punto de comenzar la construcción de su modelo predictivo para el análisis, es útil para delinear su metodología de pruebas y elaborar un plan de pruebas. La prueba debe ser impulsada por los objetivos…
Cuando haya definido los objetivos del modelo de análisis predictivo, el siguiente paso es identificar y preparar los datos que va a utilizar para construir su modelo. La secuencia general de pasos es la siguiente:Identificar las fuentes de…
Con el fin de realizar un análisis predictivo, usted tiene que obtener los datos en una forma que el algoritmo puede utilizar para construir un modelo. Para hacer eso, usted tiene que tomar un poco de tiempo para entender los datos y conocer su…
En análisis supervisadas, tanto de entrada como de salida preferidos son parte de los datos de entrenamiento. El modelo de análisis predictivo se presenta con los resultados correctos como parte de su proceso de aprendizaje. Tal aprendizaje…
Regresión lineal es un método estadístico que analiza y descubre relaciones entre dos variables. En el análisis predictivo puede ser utilizado para predecir un valor numérico futuro de una variable.Considere un ejemplo de datos que contiene dos…
Visualización de los resultados de su análisis predictivo realmente ayuda a las partes interesadas a comprender los pasos a seguir. He aquí algunas maneras de utilizar técnicas de visualización para informar de los resultados de sus modelos a…