Cómo graficar datos resumidos en un ggplot2 en r
Una característica muy conveniente de ggplot2
es su gama de funciones para resumir los datos de I en la trama. Esto significa que a menudo no tiene la validez de resumir sus datos. Por ejemplo, la altura de las barras en un histograma indica cuántas observaciones de algo que tienes en tus datos.El resumen estadístico de esto es para contar las observaciones. Los estadísticos se refieren a este proceso como hurgar en la basura, y la estadística predeterminada para geom_bar () es stat_bin ().
Análogo a la forma que cada geom tiene una estadística por defecto asociado, cada estadística también tiene un geom defecto.
Por lo tanto, esto plantea la pregunta: ¿Cómo se decide si se debe utilizar un geom o una estadística? En teoría, no importa si usted elige la geom o la estadística primera. En la práctica, sin embargo, a menudo es intuitiva para comenzar con un tipo de trama primero - en otras palabras, especificar un geom. Si a continuación desea agregar otra capa de resumen estadístico, utilice una estadística.
En esta parcela, que utilizó los mismos datos para crear un diagrama de dispersión de primera geom_point () y luego ha añadido una línea suave con stat_smooth ().
Echa un vistazo a algunos ejemplos prácticos de uso stat funciones.
| Stat | Descripción | Por defecto Geom |
|---|---|---|
| stat_bin () | Cuenta el número de observaciones en contenedores. | geom_bar () |
| stat_smooth () | Crea una línea suave. | geom_line () |
| stat_sum () | Añade valores. | geom_point () |
| stat_identity () | No hay un resumen. Parcelas de datos como se ofrecen. | geom_point () |
| stat_boxplot () | Resume los datos de un diagrama de caja y bigotes. | geom_boxplot () |
| Cómo bin datos en ggplot2 |
Ya has visto cómo utilizar stat_bin () para resumir sus datos en los contenedores, ya que esta es la estadística por defecto de geom_bar (). Esto significa que las siguientes dos líneas de código producen parcelas idénticas:
> Ggplot (terremotos, aes (x = profundidad)) + geom_bar (binwidth = 50)> ggplot (terremotos, aes (x = profundidad)) + stat_bin (binwidth = 50)
Cómo suavizar los datos R en ggplot2
los ggplot2 paquete también hace que sea muy fácil crear líneas de regresión a través de sus datos. Se utiliza el stat_smooth () función para crear este tipo de línea.
Lo interesante de stat_smooth () es que hace uso de la regresión local de forma predeterminada. R tiene varias funciones que pueden hacer esto, pero ggplot2 utiliza el loess () la función de regresión local. Esto significa que si usted desea crear un modelo de regresión lineal que tiene que decir stat_smooth () utilizar una función más suave diferente. Esto se hace con el método argumento.
Para ilustrar el uso de una más suave, arranque mediante la creación de un diagrama de dispersión de desempleo en el longley conjunto de datos:
> Ggplot (Longley, aes (x = Año, y = Empleado)) + geom_point ()
A continuación, agregue una más suave. Esto es tan simple como añadir stat_smooth () a su línea de código.
> Ggplot (Longley, aes (x = Año, Y = empleado)) ++ geom_point () + () stat_smooth
Por último, dígale stat_smooth para utilizar un modelo de regresión lineal. Esto se hace añadiendo el argumento method = "lm".
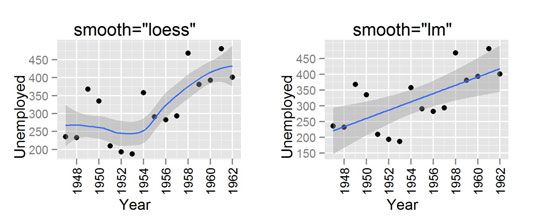
> Ggplot (Longley, aes (x = Año, Y = empleado)) ++ geom_point () + stat_smooth (method = "lm")
Cómo saber ggplot2 dejar sus datos unsummarized
A veces usted no quiere ggplot2 para resumir los datos en la trama. Esto suele suceder cuando los datos ya está pre-resumen o cuando cada línea de su trama de datos tiene que ser trazada por separado. En estos casos, usted quiere decir ggplot2 no hacer nada en absoluto, y la estadística de hacerlo es stat_identity ().
-
 Ggplot2 en r: cómo asignar datos a líneas, puntos, símbolos y más
Ggplot2 en r: cómo asignar datos a líneas, puntos, símbolos y más -
 Cómo agregar facetas, báscula y opciones en ggplot2 en r
Cómo agregar facetas, báscula y opciones en ggplot2 en r -
 Cómo agregar líneas a una parcela en r
Cómo agregar líneas a una parcela en r -
 Cómo agregar líneas de tendencia de celosía parcelas en r
Cómo agregar líneas de tendencia de celosía parcelas en r -
 Cómo emitir datos a gran formato en el r
Cómo emitir datos a gran formato en el r -
 Cómo crear un gráfico de barras utilizando ggplot2 en r
Cómo crear un gráfico de barras utilizando ggplot2 en r
Para explorar enrejado gráficos en R, primero miren el conjunto de datos integrada mtcars. Este conjunto de datos contiene 32 observaciones de los automóviles y la información sobre el motor, como el número de cilindros, automático frente a la…
La función de parcela en R tiene una escribe argumento de que controla el tipo de trama que se ve arrastrado. Por ejemplo, para crear un gráfico con líneas entre puntos de datos, utilice type = "l"- para trazar sólo los puntos, el uso type =…
LA ggplot2 geom en I dice la trama cómo quiere visualizar sus datos. Por ejemplo, se utiliza geom_bar () para hacer un gráfico de barras. En ggplot2, se puede utilizar una variedad de GEOMs predefinidos para hacer tipos estándar de trama.A geom…
El primer elemento de una ggplot2 capa es los datos. Sólo hay una regla en R para el suministro de datos para ggplot (): Sus datos deben estar en la forma de una trama de datos. Esto es diferente de gráficos de base, que permiten el trazado de los…
LA ggplot2 geom dice la trama cómo quiere visualizar sus datos en R. Por ejemplo, se utiliza geom_bar () para hacer un gráfico de barras. En ggplot2, se puede utilizar una variedad de GEOMs predefinidos para hacer tipos estándar de trama.A geom…
Porque ggplot2 no forma parte de la distribución estándar de R, usted tiene que descargar el paquete desde CRAN e instalarlo.La Red Archivo R Integral (CRAN) es una red de servidores de todo el mundo que contienen el código fuente, documentación…
Si ha descargado e importado ggplot2 para su uso en la instalación de R, se puede utilizar para trazar sus datos. Para crear un diagrama de dispersión, se utiliza el geom_point () función. Para crear un gráfico de líneas, se utiliza el…
Después de que has contado ggplot () qué datos a utilizar en R, el siguiente paso es decirle cómo sus datos corresponde a los elementos visuales de su trama. Este mapeo entre los datos y la estética visual es el segundo elemento de una ggplot2…
Después de los datos, la cartografía y GEOMs, el cuarto elemento de un ggplot2 capa en I describe cómo se deben resumir los datos. En ggplot2, que se refieren a este resumen estadístico como stat.Una característica muy conveniente de ggplot2 es…
Cuando usted tiene datos en formato de alto en R, se puede utilizar fácilmente enrejado gráficos para visualizar los subgrupos en los datos. Por ejemplo, ¿qué sucede cuando se quiere analizar más de una variable al mismo tiempo?Considere el…
El concepto básico de una ggplot2 gráfico en I es que se combinan diferentes elementos en capas. Cada capa de una ggplot2 gráfico contiene información acerca de lo siguiente:Los datos que desea trazar: por ggplot (), esto debe ser una trama de…
En ggplot2 en I, escamas controlan la forma en que sus datos se asigna a su geom. De esta manera, sus datos se asigna a algo que se puede ver (por ejemplo, líneas, puntos, colores, posición, o formas).los ggplot2 paquete es muy bueno en la…