Los datos de registro con vertedero en HDFS
Algunos de los datos que acaba en el sistema de archivos distribuido Hadoop (HDFS) podría aterrizar allí a través de las operaciones de carga de base de datos o de otros tipos de procesos por lotes, pero lo que si usted desea capturar los datos que está fluyendo en los flujos de datos de alto rendimiento, tales como datos de registro de la aplicación? Apache Flume es la manera estándar actual para hacerlo fácilmente, de manera eficiente y segura.
Apache Flume, otro proyecto de nivel superior de la Apache Software Foundation, es un sistema distribuido para agregar y mover grandes cantidades de transmisión de datos de diferentes fuentes en un almacén de datos centralizado.
Dicho de otra manera, Canal de flujo está diseñada para la ingestión continua de datos en HDFS. Los datos pueden ser cualquier tipo de datos, pero Flume es especialmente adecuado para el manejo de los datos de registro, tales como los datos de registro de los servidores web. Unidades de los datos que los procesos Flume se llaman eventos- un ejemplo de un evento es una entrada de registro.
Para entender cómo funciona Flume dentro de un cluster Hadoop, es necesario saber que Flume se ejecuta como uno o más agentes, y que cada agente tiene tres componentes enchufables: fuentes, canales y sumideros:
Fuentes recuperar los datos y enviarlo a los canales.
Canales mantener las colas de datos y sirven como conductos entre fuentes y sumideros, lo cual es útil cuando el caudal de entrada es superior a la tasa de flujo de salida.
Sumideros datos de proceso que se tomó de canales y entregarlo a un destino, como HDFS.
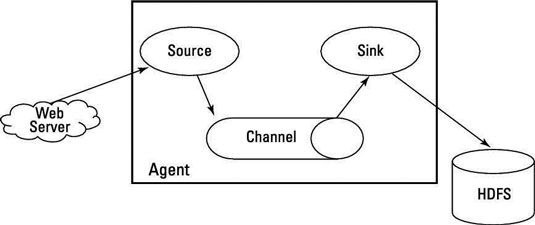
Un agente debe tener al menos uno de cada componente para funcionar, y cada agente está contenido dentro de su propia instancia de la máquina virtual de Java (JVM).
Un evento que se graba en un canal por una fuente no se elimina de ese canal hasta un fregadero lo elimina por medio de una transacción. Si se produce un fallo en la red, los canales mantienen sus eventos en cola hasta los sumideros pueden escribir a la agrupación. Un canal en memoria puede procesar eventos rápidamente, pero es volátil y no se puede recuperar, mientras que un canal basado en archivos ofrece persistencia y puede ser recuperado en caso de fallo.
Cada agente puede tener varias fuentes, canales y sumideros, y aunque una fuente puede escribir en muchos canales, un fregadero puede tomar datos de un solo canal.
Un agente es sólo una JVM que ejecuta Flume y los sumideros para cada nodo de agente en el cluster Hadoop enviaremos los datos de nodos de colección, que agregar los datos de muchos agentes antes de escribirla en HDFS, donde puede ser analizada por otras herramientas de Hadoop.
Los agentes pueden ser encadenados juntos para que el fregadero de un agente envía datos a la fuente de otro agente. Avro, marco de llamada y serialización a distancia de Apache, es la forma habitual de envío de datos a través de una red con Flume, porque sirve como una herramienta útil para la serialización eficiente o transformación de datos en un formato binario compacto.
En el contexto de Flume, la compatibilidad es importante: Un evento Avro requiere una fuente de Avro, por ejemplo, y un fregadero debe entregar eventos que sean apropiados a su destino.
Lo que hace esta gran cadena de fuentes, canales y sumideros de trabajo es la configuración del agente Flume, que se almacena en un archivo de texto local que está estructurado como un archivo de propiedades Java. Puede configurar varios agentes en el mismo archivo. Mira a un archivo de muestra, que lleva el nombre aforador-agent.conf - que está establecido para configurar un agente llamado chamán:
# Identificar los componentes de chamán agente: shaman.sources = netcat_s1shaman.sinks = hdfs_w1shaman.channels = en-mem_c1 # Configurar la fuente: shaman.sources.netcat_s1.type = netcatshaman.sources.netcat_s1.bind = localhostshaman.sources.netcat_s1. port = 44444 # Describa el fregadero: shaman.sinks.hdfs_w1.type = hdfsshaman.sinks.hdfs_w1.hdfs.path = hdfs: //shaman.sinks.hdfs_w1.hdfs.writeFormat = Textshaman.sinks.hdfs_w1.hdfs.fileType = DataStream # Configure un canal que amortigua los eventos en la memoria: shaman.channels.in-mem_c1.type = memoryshaman.channels.in-mem_c1.capacity = 20000shaman.channels.in-mem_c1.transactionCapacity = 100 # Enlazar la fuente y sumidero para el canal: shaman.sources.netcat_s1.channels = en-mem_c1shaman.sinks.hdfs_w1.channels = en-mem_c1
El archivo de configuración incluye las propiedades de cada fuente, el canal, y el lavabo en el agente y especifica cómo están conectados. En este ejemplo, chamán agente tiene una fuente que escucha de datos (mensajes a netcat) en el puerto 44444, un canal que amortigua los datos de eventos en la memoria, y un lavabo que registra datos de eventos a la consola.
Este archivo de configuración podría haber sido utilizado para definir varios agentes- aquí, usted está configurando un solo mantener las cosas simples.
Para iniciar el agente, utilice un script de shell llamado canal-ng, que se encuentra en el directorio bin de la distribución Flume. Desde la línea de comandos, ejecute el comando agente, especificando la ruta de acceso al archivo de configuración y el nombre del agente.
El comando de ejemplo siguiente inicia el agente Flume:
canal-ng agente -f /-n chamán
Registro del agente Flume debe tener entradas que verifican que la fuente, el canal, y el fregadero comenzaron con éxito.
A fin de probar la configuración, puede telnet al puerto 44444 desde otro terminal y enviar Flume un evento mediante la introducción de una cadena de texto arbitraria. Si todo va bien, la salida testamento original Flume terminal de el evento en un mensaje de registro que usted debería ser capaz de ver en el registro del agente.
-
 Compañía telefónica wan tecnologías: la conmutación de circuitos
Compañía telefónica wan tecnologías: la conmutación de circuitos - Apache bigtop y Hadoop
-
") Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS)
Los bloques de datos en el sistema de archivos distribuidos Hadoop (HDFS) -
 federación") Hadoop distribuido sistema de archivos (HDFS) federación
Hadoop distribuido sistema de archivos (HDFS) federación - Hadoop de archivos distribuido comandos de shell del sistema
- Hadoop Sqoop para grandes datos
El sistema de archivos distribuido Hadoop es un resistente, enfoque versátil, agrupadas a la gestión de archivos en un entorno de datos grande. HDFS no es el destino final de los archivos. Más bien, es un servicio de datos que ofrece un conjunto…
Apache Oozie está incluido en todas las distribuciones de Hadoop importante, incluyendo Apache Bigtop. En el clúster Hadoop, instale el servidor Oozie en un nodo de borde, donde usted también ejecutar otras aplicaciones de cliente con los datos…
Listo para sumergirse en la importación de datos con Sqoop? Empieza por tomar un vistazo a la figura, que ilustra los pasos en una operación típica Sqoop importación de un RDBMS o un sistema de almacenamiento de datos. Nada demasiado complicado…
La forma HDFS se ha establecido, se descompone muy grandes archivos en bloques grandes (por ejemplo, la medición de 128 MB), y almacena tres copias de estos bloques en diferentes nodos del clúster. HDFS no tiene conciencia del contenido de estos…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
HDFS es uno de los dos componentes principales de la Hadoop de armazón y el otro es el paradigma computacional conocido como MapReduce. LA sistema de archivos distribuido es un sistema de archivos que gestiona el almacenamiento a través de un…
Hadoop Distributed File System (HDFS) está diseñado para almacenar datos en barato y más fiable, hardware. Barato tiene un anillo atractivo a la misma, pero plantea preocupaciones sobre la fiabilidad del sistema en su conjunto, especialmente para…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Hacer un balance de el tipo de datos que está tratando con su proyecto de datos grande. Muchas organizaciones están reconociendo que una gran cantidad de datos generados internamente no se ha utilizado en todo su potencial en el pasado.Mediante el…
Agentes juegan un papel importante en la arquitectura Unicenter TNG. Agentes especializados programas que Unicenter TNG utiliza para monitorear objetos administrados, que comprenden los recursos de red tales como servidores de bases de datos,…
Aunque no se puede mezclar o cambiar el nombre de los canales de color en Photoshop CS6, puede hacerlo con canales de tintas planas y alfa. Para mover un canal de tinta plana o alfa, simplemente arrastre hacia arriba o hacia abajo en el panel…
La relación entre un agente de bienes raíces y un cliente se llama relación fiduciaria. Fiduciaria significa siervo fiel, y un agente es un fiduciario del cliente. En el sector inmobiliario, un corredor o un vendedor puede ser el agente de un…