Los tipos de datos de cerdo de Hadoop y sintaxis
Tipos de datos de cerdo componen el modelo de datos para cómo Pig piensa en la estructura de los datos que se está procesando. Con Cerdo, el modelo de datos se define al cargar los datos. Cualquier dato se carga en cerdo del disco va a tener un esquema y estructura particular. Cerdo tiene que entender que la estructura, así que cuando usted hace la carga, los datos pasa automáticamente a través de un mapeo.
Por suerte para usted, el modelo de datos de cerdo es lo suficientemente rico como para manejar casi cualquier cosa lanzado su camino, incluyendo mesa- como las estructuras y estructuras de datos jerárquicos anidados. En términos generales, sin embargo, los tipos de datos de cerdo se pueden dividir en dos categorías: los tipos escalares y tipos complejos. Scalar tipos contienen un solo valor, mientras que complejo tipos contienen otros tipos, tales como los tipos Tuple, Bolsa y Mapa enumeran a continuación.
Latín de cerdo tiene estos cuatro tipos en su modelo de datos:
Atom: Un átomo es cualquier valor único, como una cadena o un número - 'Diego', por ejemplo. Valores atómicos de cerdo son tipos escalares que aparecen en la mayoría de los lenguajes de programación - int, long, float, double, chararray y bytearray, por ejemplo.
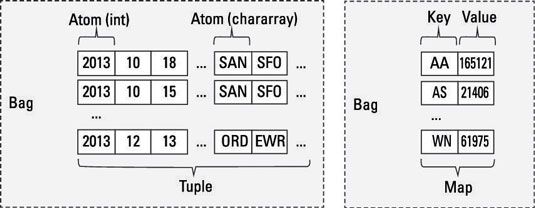
Tupla: LA tupla es un disco que consiste en una secuencia de campos. Cada campo puede ser de cualquier tipo - 'Diego', 'Gómez', o 6, por ejemplo). Piense en una tupla como una fila en una tabla.
Bolso: LA bolso es una colección de tuplas no únicos. El esquema de la bolsa es flexible - cada tupla en la colección puede contener un número arbitrario de campos, y cada campo puede ser de cualquier tipo.
Mapa: Un mapa es un conjunto de pares de valores clave. Cualquier tipo puede ser almacenado en el valor, y la clave debe ser único. La clave de un mapa debe ser un chararray y el valor puede ser de cualquier tipo.
La cifra ofrece algunos buenos ejemplos de los tipos de datos Tuple, Bolsa, y Mapa, también.
El valor de todos estos tipos también puede ser nulo. La semántica para nulo son similares a los utilizados en SQL. El concepto de null en Pig significa que el valor es desconocido. Nulos pueden aparecen en los datos en los casos en que los valores son ilegibles o irreconocible - por ejemplo, si usted fuera a utilizar un tipo de datos incorrecto en la declaración de carga.
Null podría ser utilizado como un marcador de posición hasta que se añada de datos o como un valor para un campo que es opcional.
Latín de cerdo tiene una sintaxis simple con la semántica de gran alcance que utilizará para llevar a cabo dos operaciones principales: el acceso y transformar los datos.
En un contexto de Hadoop, el acceso datos significa que permite a los desarrolladores para cargar, almacenar y datos de la secuencia, mientras que transformadora significa datos aprovechando la capacidad del cerdo para agrupar, unir, combinar, dividir, filtrar y ordenar los datos. La tabla da una visión general de los operadores asociados a cada operación.
| Operación | Operador | Explicación |
|---|---|---|
| Acceso a los datos | Load / Store | Leer y escribir datos en el sistema de archivos |
| DUMP | Escribe la salida a la salida estándar (stdout) | |
| STREAM | Enviar todos los registros a través binaria externa | |
| Transformaciones | PARA CADA | Aplicar la expresión de cada registro y la salida de una o morerecords |
| FILTRO | Aplicar predicado y quitar registros que no meetcondition | |
| GRUPO / COGROUP | Registros de agregado con la misma clave de uno o moreinputs | |
| ÚNETE | Unir dos o más registros en base a una condición | |
| CRUZAR | Producto cartesiano de dos o más entradas | |
| ORDEN | Ordenar registros basados en clave | |
| DISTINCT | Eliminar registros duplicados | |
| UNIÓN | Combinar dos conjuntos de datos | |
| SPLIT | Los datos se dividen en dos o más bolsas a base de predicado | |
| LÍMITE | subconjunto del número de registros |
Pig también ofrece unos pocos operadores que son útiles para la depuración y solución de problemas, como se muestra:
| Operación | Operador | Descripción |
|---|---|---|
| Depuración | DESCRIBE | Devuelva el esquema de una relación. |
| DUMP | Volcar el contenido de una relación a la pantalla. | |
| EXPLICAR | Mostrar los planes de ejecución de MapReduce. |
Parte del cambio de paradigma de Hadoop es que aplique el esquema de lectura en lugar de carga. De acuerdo a la vieja manera de hacer las cosas - la manera RDBMS - al cargar los datos en su sistema de base de datos, debe cargarlo en un conjunto bien definido de tablas. Hadoop permite almacenar todo lo que los datos en bruto por adelantado y aplicar el esquema en Leer.
Con Cerdo, usted hace esto durante la carga de los datos, con la ayuda del operador CARGA.
La declaración USO opcional define cómo asignar la estructura de datos en el archivo en el modelo de datos de Cerdo - en este caso, la estructura de datos PigStorage (), que analiza los archivos de texto delimitado. (Esta parte de la instrucción USING se refiere a menudo como una Func LOAD y funciona de manera similar a un deserializador personalizado.)
El opcional AS cláusula define un esquema para los datos que se asigna. Si usted no utiliza una cláusula AS, que está básicamente diciendo la Func CARGA predeterminado para esperar un archivo de texto plano que está delimitado ficha. Sin esquema proporcionado, los campos deben ser referenciados por posición, porque no hay ningún nombre definido.
Utilizando como cláusulas significa que usted tiene un esquema en el lugar en tiempo de lectura para sus archivos de texto, lo que permite a los usuarios empezar a trabajar rápidamente y proporciona el modelado esquema ágil y flexibilidad, de modo que puede agregar más datos para su análisis.
El operador LOAD opera sobre el principio de evaluación perezosa, también conocido como llamada por necesidad. Ahora perezoso no suena particularmente digno de elogio, pero lo único que significa es que se demora la evaluación de una expresión hasta que realmente lo necesita.
En el contexto del ejemplo del cerdo, lo que significa que después de que se ejecuta la sentencia LOAD, se mueve sin datos - nada se desvía alrededor - hasta que se encuentre una declaración a escribir datos. Usted puede tener una secuencia de comandos de cerdo que es una página de largo lleno de transformaciones complejas, pero nada es ejecutado hasta que se encuentre la instrucción DUMP o STORE.



Antes de que pueda ejecutar su primer script Cerdo en Hadoop, es necesario tener una manija en cómo los programas de cerdo pueden ser empaquetados con el servidor de cerdo.Cerdo tiene dos modos de ejecutar secuencias de comandos:Modo local: Todos…
Hadoop, un marco de software de código abierto, utiliza HDFS (el sistema de archivos distribuido Hadoop) y MapReduce para analizar grandes volúmenes de datos en clústeres de hardware que la mercancía es, en un entorno de computación…
Bases de datos NoSQL no se restringen a un filas # 8208 y # 8208 enfoque columnas. Están diseñados para manejar una gran variedad de datos, incluidos los datos cuya estructura cambia con el tiempo y cuyas interrelaciones aún no se conocen.Bases…
Almacenes de datos NoSQL originalmente suscribieron a la noción " Apenas diga no a SQL " (parafraseando a partir de una campaña publicitaria anti-drogas en la década de 1980), y eran una reacción a las limitaciones percibidas de bases de datos…
Cerdo latín es el idioma para programas de cerdo. Cerdo traduce el guión Pig Latin en puestos de trabajo MapReduce que pueda ser ejecutado dentro del clúster Hadoop. Si viene con cerdo América, el equipo de desarrollo sigue tres principios…
El lenguaje de programación cerdo está diseñado para manejar cualquier tipo de datos arrojó su camino - estructurada, semiestructurada, los datos no estructurados, lo que sea. Programas de cerdo puede ser envasados en tres formas…
Hadoop es un ecosistema rico y evolucionando rápidamente con un conjunto cada vez mayor de nuevas aplicaciones. En lugar de tratar de mantenerse al día con todos los requisitos para nuevas capacidades, cerdo está diseñado para ser extensible a…
HBase es una no relacional (columnar) base de datos distribuida, que utiliza HDFS como su almacén de persistencia para proyectos de grandes datos. Es el modelo de Google BigTable y es capaz de albergar mesas muy grandes (miles de millones de…
Al considerar las capacidades de Hadoop para trabajar con datos estructurados (o trabajar con datos de cualquier tipo, para el caso), recuerda las características fundamentales de Hadoop: Hadoop es, ante todo, una plataforma de almacenamiento y…
Hadoop es más de MapReduce y HDFS (Hadoop Distributed File System): Es también una familia de proyectos relacionados (un ecosistema, en realidad) para la computación distribuida y el procesamiento de datos a gran escala. La mayoría (pero no…
Después de que el clúster Hadoop está instalado y en funcionamiento, puede ejecutar su primer programa de Hadoop. Esta aplicación es muy sencilla, y calcula el total de millas voladas para todos los vuelos realizados en un año. El año está…
Cuando se utiliza un programa de base de datos como el acceso de 2013, no se puede simplemente comenzar a introducir los datos. En lugar de ello, es necesario crear un diseño de base de datos relacional, dividiendo su información en una o varias…