Tome HBase para una prueba de funcionamiento
Aquí, usted descubre cómo descargar e implementar HBase en modo autónomo. Es increíblemente fácil de instalar HBase y comenzar a usar la tecnología. Hemos de tener en cuenta que HBase suele desplegar en un clúster de servidores de las materias primas, aunque también se puede implementar fácilmente HBase en una configuración autónoma en cambio, a efectos de aprendizaje o de demostración.
Como Hadoop, HBase soporta Linux principalmente pero poder utilizar Windows en entornos no productivos si primero descargar Cygwin. Cygwin ofrece a los usuarios de Microsoft Windows una cáscara de Unix con todos sus comandos y utilidades. Así que si usted sigue la guía de inicio rápido, tendrá que descargar la última versión HBase.
Tienes la oportunidad de elegir dónde instalar HBase. Resulta, sin embargo, que si quieres que las cosas funcionan en modo autónomo, tendrá que editar un par de archivos antes de que puedas comenzar HBase. El primer archivo se muestra en la siguiente lista. Los cambios que usted querrá hacer aparecerán en negrita para hacer que se destacan:
hbase.rootdir file: /// home / BiAdmin / mi-HBase locales / HBase-data hbase.cluster.distributed cierto hbase.zookeeper.property.clientPort 2222 Propiedad de config zoo.cfg de ZooKeeper. El puerto en el que los clientes se conectarán.hbase.zookeeper.property.dataDir / home / BiAdmin / mi-local-HBase / cuidador del zoológico hbase.zookeeper.quorum bivm
Se especifica un directorio en el sistema de archivos local para almacenar los datos HBase. En entornos de producción, esta propiedad sería apuntar a los HDFS para el almacén de datos. En aras de la ilustración, el modo pseudo-distribuido causará HBase para iniciar una instancia de RegionServer, una instancia de MasterServer, y un proceso Zookeeper.
Además, es necesario especificar el directorio donde Zookeeper almacenará sus datos () y una lista de los servidores en los que se ejecutará Zookeeper para formar el quórum (). Para autónomo, sólo se especifica el servidor Zookeeper sola.
Primeros pasos con HBase en modo autónomo es muy sencillo, en parte porque HBase gestiona Zookeeper para usted. Puede descargar una versión Zookeeper independiente y señalar HBase a ella, pero para instalaciones independientes, usted encontrará mucho más fácil dejar que HBase gestionar Zookeeper para usted.
Para cristalizar la decisión de dejar HBase gestionar Zookeeper para usted, aquí es cómo establecer una variable de entorno en otro archivo HBase. La siguiente lista muestra lo que hay que añadir:
# Dile HBase si debe gestionar su propia instancia de Zookeeper o not.export HBASE_MANAGES_ZK = true # La aplicación java para usar. Java 1.6 required.export JAVA_HOME = / opt / ibm / BigInsights / jdk
Usted tendrá que asegurarse de que apuntan a su JDK elegido. Por último, es necesario especificar el nombre de su sistema Linux en otro archivo. (En un entorno de producción totalmente distribuida, este archivo tendrá una línea por línea lista de todos los servidores en los que HBase puede iniciar el proceso RegionServer sucesivamente.)
Ahora puede poner en marcha HBase y probar su instalación. Para iniciar HBase, utilice el script tal como se expone en la siguiente lista.
$ Cd $ INSTALL_DIR / HBase-0.94.7 / bin $ ./start-hbase.shbivm: a partir empleado del zoológico, el registro en /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/ maestro HBase-BiAdmin-empleado del zoológico-bivm.outstarting, el registro en /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/hbase-biadmin-master-bivm.outlocalhost: regionserver partida, el registro en /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/hbase-biadmin-regionserver-bivm.out
Tenga en cuenta que la primera línea tiene un cd (cambiar directorio) de comandos que se mueve a una variable de entorno. Usted tiene que fijar esa variable en el directorio de instalación real de HBase o escriba la ruta completa.
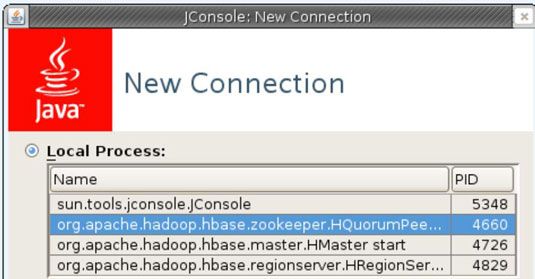
A continuación, utilice la herramienta JConsole, que viene incluido con Java, para realizar una comprobación rápida en qué procesos se están ejecutando después de que finalice la secuencia de comandos. Puede iniciar la herramienta JConsole escribiendo el siguiente comando: $ JAVA_HOME / bin / jconsole.
JConsole revela que los tres procesos que el guión reclamaba para comenzar son de hecho funcionando - el cuidador del zoológico, el maestro, y los procesos RegionServer.
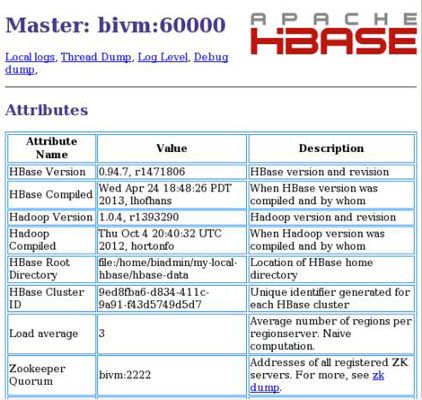
Para poner HBase través de sus pasos, se interactúa con los tres procesos HBase, empezando por el MasterServer. Por defecto, el MasterServer informa sobre el estado del sistema a través de una interfaz de usuario del navegador en el puerto número 60010. En el ejemplo, se puede confirmar que el MasterServer funciona correctamente introduciendo el siguiente URL en un navegador web: http: // bivm : 60010 /. Si lo hace, nos lleva a la información que usted ve aquí.



HBase es una tecnología poderosa y flexible, pero que acompaña a esta flexibilidad es el requisito para la configuración y puesta a punto adecuada. Es hora de que algunas pautas generales para configurar grupos HBase. Su "kilometraje" puede…
HBase y la tecnología de base de datos relacional (como Oracle, DB2, MySQL y por nombrar sólo algunos) realmente no se pueden comparar del todo bien. A pesar del cliché , es realmente un caso de comparar manzanas con naranjas. HBase es una NoSQL…
Cualquier instalación seria HBase requiere un poco de configuración estándar en el clúster y en los nodos individuales. Algunos ejemplos se proporcionan aquí. Primero eche un vistazo a la supervisión y la gestión.Herramientas para supervisar…
Sqoop se puede utilizar para transformar un esquema de base de datos relacional en un esquema HBase. Por supuesto, el objetivo principal aquí es demostrar cómo Sqoop puede importar datos de un RDBMS o almacén de datos directamente en HBase, pero…
El modelo de datos HBase lógica es simple pero elegante, y proporciona un mecanismo de almacenamiento de datos natural para todo tipo de datos - conjuntos de datos grandes, especialmente estructurados. Todas las partes del modelo de datos convergen…
RegionServers son una cosa, pero también hay que echar un vistazo a cómo funcionan las distintas regiones. En HBase, una mesa es a la vez la propagación a través de una serie de RegionServers además de estar constituida por regiones…
RegionServers son los procesos de software (a menudo llamados demonios) que activan para almacenar y recuperar datos en HBase (Hadoop base de datos). En entornos de producción, cada RegionServer se implementa en su propio nodo de cómputo dedicado.…
Almacenes de datos HBase constan de una o más tablas, que están indexados por claves de fila. Los datos se almacenan en filas con columnas y filas puede tener múltiples versiones. Por defecto, el control de versiones de filas de datos se…
En un universo Hadoop, nodos esclavos son los que los datos Hadoop se almacena y donde el procesamiento de datos se lleva a cabo. Los siguientes servicios permiten nodos esclavos para almacenar y procesar datos:NodeManager: Coordina los recursos…
HBase es una no relacional (columnar) base de datos distribuida, que utiliza HDFS como su almacén de persistencia para proyectos de grandes datos. Es el modelo de Google BigTable y es capaz de albergar mesas muy grandes (miles de millones de…
HBase está escrito en Java, un lenguaje elegante para la construcción de tecnologías distribuidas como HBase, pero la cara él - no todo el mundo que quiera aprovechar las innovaciones HBase es un desarrollador Java. Es por eso que hay un rico…
A partir de un análisis de HBase (base de datos Hadoop) arquitectura describiendo RegionServers lugar del MasterServer puede sorprender. El termino RegionServer parecería implicar que depende (y es secundaria a) la MasterServer y que, por lo tanto…