Los datos estructurados en un entorno de datos grande
El termino datos estructurados
Conteúdo
Fuentes de datos de gran estructurado
Aunque esto puede parecer como de costumbre, en la realidad, los datos estructurados está asumiendo un nuevo papel en el mundo de los grandes datos. La evolución de la tecnología ofrece nuevas fuentes de datos estructurados que se producen - a menudo en tiempo real y en grandes volúmenes. Las fuentes de los datos se dividen en dos categorías:
PC- o máquina generadas: Datos de máquina generadas generalmente se refiere a los datos que se crea por una máquina sin intervención humana.
Humano generadas: Se trata de datos que los seres humanos, en la interacción con las computadoras, de suministro.
Algunos expertos sostienen que existe una tercera categoría que es un híbrido entre máquina y humano. Aquí, sin embargo, estamos preocupados por las dos primeras categorías.
Datos estructurados generados por máquina pueden incluir lo siguiente:
Datos del sensor: Los ejemplos incluyen las etiquetas de identificación de radio frecuencia, contadores inteligentes, dispositivos médicos, y los datos de Sistema de Posicionamiento Global. Las empresas están interesadas en esto para la gestión de la cadena de suministro y control de inventario.
datos de registro web: Cuando los servidores, aplicaciones, redes, etc. operan, capturan todo tipo de datos sobre su actividad. Esto puede equivaler a grandes volúmenes de datos que pueden ser útiles, por ejemplo, para hacer frente a los acuerdos de nivel de servicio o para predecir las brechas de seguridad.
Punto de venta de datos: Cuando el cajero desliza el código de barras de cualquier producto que se compra, se genera todos los datos asociados con el producto.
Datos financieros: Muchos de los sistemas financieros son ahora programmatic- se operan sobre la base de reglas predefinidas que automatizan los procesos. Los datos de-comercio es un buen ejemplo de esto. Contiene datos estructurados, como el símbolo de la empresa y el valor del dólar. Algunos de estos datos es la máquina generado, y algunos es humano generado.
Ejemplos de datos humanos generados estructurados pueden incluir lo siguiente:
Datos de entrada: Esto es cualquier pedazo de datos que una entrada de fuerza humana en una computadora, como nombre, edad, ingresos, respuestas a la encuesta no de forma libre, y así sucesivamente. Estos datos pueden ser útiles para entender el comportamiento básico del cliente.
Click-flujo de datos: Los datos se genera cada vez que hace clic en un enlace en una página web. Estos datos pueden ser analizados para determinar el comportamiento del cliente y los patrones de compra.
Los datos relacionados con el juego: Cada movimiento que haces en un juego se puede grabar. Esto puede ser útil en la comprensión de cómo los usuarios finales se mueven a través de una cartera de juegos.
Cuando se toma junto con millones de otros usuarios que presentan la misma información, el tamaño es astronómico. Además, muchos de estos datos tiene un componente en tiempo real a lo que puede ser útil para la comprensión de los patrones que tienen el potencial de los resultados de la predicción.
La conclusión es que este tipo de información puede ser de gran alcance y puede ser utilizado para muchos propósitos.
El papel de las bases de datos relacionales en grandes datos
La persistencia de datos se refiere a la forma en una base de datos conserva versiones de sí mismo cuando se modifica. El gran abuelo de los almacenes de datos persistentes es el sistema de gestión de bases de datos relacionales. En sus inicios, la industria de la computación utiliza lo que ahora se consideran técnicas primitivas para la persistencia de datos.
El modelo relacional fue inventado por Edgar Codd, un científico de IBM, en la década de 1970 y fue utilizado por IBM, Oracle, Microsoft y otros. Todavía está en amplio uso hoy y juega un papel importante en la evolución de los datos grandes. La comprensión de la base de datos relacional es importante porque otros tipos de bases de datos se utilizan con grandes volúmenes de datos.
En un modelo relacional, los datos se almacenan en una tabla. Esta base de datos contendría una esquema - es decir, una representación estructural de lo que está en la base de datos. Por ejemplo, en una base de datos relacional, el esquema define las tablas, los campos de las tablas, y las relaciones entre los dos.
Los datos se almacenan en columnas, una para cada atributo específico. Los datos también se almacena en la fila. La primera tabla almacena información-producto de la segunda almacena información demográfica. Cada uno tiene diferentes atributos. Cada tabla puede actualizarse con nuevos datos, y los datos se pueden borrar, leer, y actualizado. Esto a menudo se lleva a cabo en un modelo relacional utilizando un lenguaje de consulta estructurado (SQL).
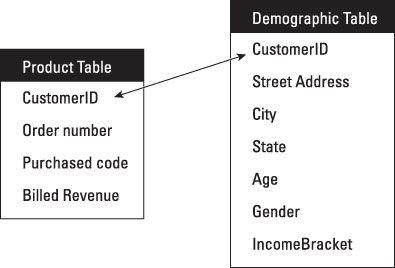
Otro aspecto de la modelo relacional con SQL es que las tablas se pueden consultar mediante una clave común. La clave común en las mesas es CustomerID.
Usted puede enviar una consulta, por ejemplo, para determinar el sexo de clientes que han comprado un producto específico. Podría ser algo como esto:
Seleccione CustomerID, Estado, Género, producto de la "tabla demográfica", "tabla de productos", donde Producto = XXYY



Cada área de la tecnología está en constante cambio, y el almacenamiento de datos no es una excepción. Debido a que el almacenamiento de datos está al borde de una nueva generación de tecnologías, debe familiarizarse con algunas de las…
La organización de los servicios de datos y herramientas, la capa 3 de la pila de datos grande, capturar, validar, y montar varios elementos de datos grandes en colecciones contextualmente relevantes. Dado que los datos de grande es masiva, las…
Esta no es la primera vez en la historia reciente que han surgido y superar las ineficiencias RDBMS nuevos tipos de productos de base de datos. De vuelta en la década de 1980, se identificó una clase de aplicaciones en las que RDBMS productos…
Las bases de datos no relacionales no se basan en la tabla / modelo clave endémica de RDBMS (sistemas de gestión de base de datos relacional). En resumen, los datos de la especialidad en el gran mundo de los datos requiere persistencia…
Aquí están algunos de los principales productos de bases de datos relacionales que es posible que desee utilizar para el almacenamiento de datos. Casi todos estos proveedores han, durante los últimos años, adquirió productos adicionales,…
Como la computación se movió en el mercado comercial, los datos se almacenan en archivos planos que impusieron ninguna estructura. Hoy en día, los grandes datos requiere estructuras de datos manejables. Cuando las empresas necesitan para llegar a…
Con la llegada de grandes volúmenes de datos, los modelos de implementación para la gestión de datos están cambiando. El almacén de datos tradicional se lleva a cabo normalmente en un solo sistema, grande dentro del centro de datos. Los costes…
El mercado de almacenamiento de datos de hecho ha empezado a cambiar y evolucionar con la llegada de grandes datos. En el pasado, simplemente no era económico para las empresas a almacenar la cantidad masiva de datos de un gran número de sistemas…
Muchas empresas están explorando problemas de datos grandes y dar con algunas soluciones innovadoras. Ahora es el momento de prestar atención a algunos mejores prácticas, o principios básicos, que serán muy útiles a medida que comienza su…
Big Data permite a las organizaciones almacenar, gestionar y manipular grandes cantidades de datos dispares a la velocidad adecuada y en el momento adecuado. Para obtener los conocimientos adecuados, grandes datos se suelen dividirse por tres…
MySQL es un sistema de gestión de bases de datos relacionales (RDBMS). El servidor MySQL puede manejar muchas bases de datos al mismo tiempo. De hecho, muchas personas pueden tener diferentes bases de datos gestionadas por un único servidor MySQL.…
Cuando se utiliza un programa de base de datos como el acceso de 2013, no se puede simplemente comenzar a introducir los datos. En lugar de ello, es necesario crear un diseño de base de datos relacional, dividiendo su información en una o varias…