¿Cómo evaluar las diferencias en sus datos con r
Para comprobar el modelo de datos que ha creado con ANOVA (análisis de varianza), puede utilizar R Resumen ()
Conteúdo
> Resumen valor (AOVModel) Df Sum Sq Mean Square F Pr (> F) spray5 2669 533,8 34,7 lt; 2e-16 *** residuos 66 1015 15.4 --- Signif. códigos: 0 '***' 0.001 '**' 0.01 '*' 0.05 ''. 0.1 '' 1
R que imprime la tabla de análisis de varianza que, en esencia, le indica si los diferentes términos pueden explicar una parte significativa de la varianza en los datos. Esta tabla le indica solamente algo sobre el término, pero nada acerca de las diferencias entre los diferentes aerosoles. Para eso, hay que cavar un poco más profundo.
Cómo comprobar tablas modelo de datos
Con el model.tables () función, puede echar un vistazo a los resultados de los niveles individuales de los factores. La función le permite crear de dos mesas- diferente o bien se mira el resultado medio estimado para cada grupo, o nos fijamos en la diferencia con la media global.
Para saber cuánto efecto tiene cada pulverización, se utiliza el siguiente código:
> Model.tables (AOVModel, type = "efectos") Mesas de effectsspraysprayA BCDE F5.000 5.833 -7.417 -4.583 -6.000 7.167
Aquí vemos que, por ejemplo, rociar E dio como resultado, en promedio, en seis errores menos que la media de todos los campos. Por otra parte, en los campos donde se utilizó pulverización A, los agricultores encontraron, en promedio, cinco errores más en comparación con la media global.
Para obtener los medios modelados por grupo y la media general, sólo tiene que utilizar el valor del argumento type = "medios" en lugar de type = "efectos".
Cómo mirar a las diferencias individuales en los datos
Un agricultor probablemente no considerar la compra de un aerosol, pero ¿qué pasa con aerosol D? Aunque los aerosoles E y C parecen estar mejor, también pueden ser mucho más caros. Para probar si las diferencias por pares entre los aerosoles son significativos, se utiliza la prueba honesta de Tukey diferencia significativa (HSD). los TukeyHSD () función le permite hacer eso muy fácilmente, así:
> Las comparaciones lt; - TukeyHSD (Modelo)
los Las comparaciones objeto ahora contiene una lista en la que cada elemento es el nombre de uno de los factores en el modelo. En el ejemplo, usted tiene sólo un elemento, llamado rociar. Este elemento contiene, para cada combinación de los aerosoles, los siguientes:
La diferencia entre las medias.
El nivel inferior y superior del intervalo de confianza del 95 por ciento en torno a esa diferencia de medias.
El p-valor que indica si esta diferencia es significativamente diferente de cero. Este valor p se ajusta utilizando el método de Tukey (de ahí el nombre de la columna p adj).
Usted puede extraer toda esa información utilizando los métodos clásicos de extracción. Por ejemplo, se obtiene la información acerca de la diferencia entre D y C de esta manera:
> Las comparaciones $ aerosol ['D-C',] difflwrupr p adj2.8333333 -1,8660752 7,5327418 0,4920707
Esa diferencia no se ve impresionante, si le preguntas a Tukey.
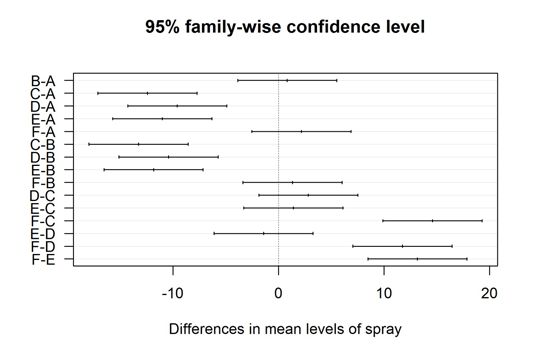
Cómo graficar las diferencias
los TukeyHSD objeto tiene otra característica interesante: puede ser trazada. No te molestes en busca de una página de ayuda de la función de trama - todo lo que encontramos es una frase: " Hay un método parcela ". Pero definitivamente funciona! Pruébalo así:
> Argumentales (comparaciones, las = 1)
Usted ve la salida de esta línea simple. Cada línea representa la diferencia media entre ambos grupos con el intervalo de confianza de acuerdo. Cada vez que el intervalo de confianza no incluye cero (la línea vertical), la diferencia entre ambos grupos es significativa.
Puede utilizar algunos de los parámetros gráficos para hacer la trama más legible. Específicamente, la las parámetro es útil aquí. Estableciéndola en 1, te aseguras de todas las etiquetas de los ejes se imprimen horizontalmente para que pueda leer en realidad ellos.
-
 ¿Cómo explicar los resultados de los análisis predictivos de regresión r
¿Cómo explicar los resultados de los análisis predictivos de regresión r - Cómo analizar las variaciones de datos en modelos con r
- ¿Cómo comparar datos apareados con r
- Cómo comparar dos muestras de datos con la prueba t de r
- Cómo evaluar los datos lineales con r
-
 Cómo modelar las relaciones de datos lineales con r
Cómo modelar las relaciones de datos lineales con r
Aparte de la descripción de las relaciones, los modelos también pueden usarse para predecir los valores para los nuevos datos. Por eso, muchos sistemas modelo en I utilizan la misma función, convenientemente llamado predecir (). Cada modelado de…
Al romper seguridad de sus datos en intervalos de R, usted todavía pierde alguna información. Sin embargo, la forma más completa de la descripción de sus datos es mediante la estimación de la la función de densidad de probabilidad (PDF) o…
Si conoces las desviaciones estándar para dos muestras de población, entonces usted puede encontrar un intervalo de confianza (IC) de la diferencia entre sus medios, o promedios. El objetivo de muchas encuestas estadísticas y estudios es comparar…
Al sacar conclusiones sobre una población a partir de muestras elegidas al azar (un proceso llamado inferencia estadística), Puede utilizar dos métodos: intervalos de confianza y pruebas de hipótesis.Intervalos de confianzaLA intervalo de…
Usted puede encontrar un intervalo de confianza (IC) para la diferencia entre las medias, o medias, de dos muestras de población, aun cuando las desviaciones estándar poblacionales son desconocidas y / o los tamaños de las muestras son pequeños.…
Estadísticas II es a menudo sobre el análisis de datos, y el truco es saber cuándo utilizar el método de análisis. La siguiente tabla le ayuda a comparar, el contraste y decidir qué análisis de datos para usar y cuándo. Úsalo para una…
La siguiente tabla proporciona una lista de algunos de los procedimientos más utilizados dentro del menú Análisis de IBM SPSS Statistics, que es una aplicación que realiza el análisis estadístico de los datos.SubmenúÚtil para . . .Código…
En SPSS Statistics, el nivel de medición de las variables define qué se deben utilizar las estadísticas de resumen y gráficos. La siguiente tabla proporciona definiciones, ejemplos, las estadísticas de resumen apropiadas, y gráficos para el…
Estadísticas II es a menudo sobre el análisis de datos, y el truco es saber cuándo utilizar el método de análisis. La siguiente tabla le ayuda a comparar, el contraste y decidir qué análisis de datos para usar y cuándo. Úsalo para una…
Los no apareados (independiente de la muestra) pruebas t, ANOVA de una vía, ANCOVA, y sus homólogos no paramétricos se ocupan de las comparaciones entre dos o más grupos de independiente muestras de datos, como los diferentes grupos de sujetos,…
Puede ejecutar las pruebas de la t de Student utilizando el software estadístico típica e interpretar la salida producida. En este ejemplo, podrás usar el OpenStat paquete de software.La idea básica de una prueba tTodas las pruebas t de Student…
El llamado " análisis unidireccional de varianza " (ANOVA) se usa cuando se comparan tres o más grupos de números. Al comparar los dos grupos (A y B), se prueba la diferencia (A - B) entre los dos grupos con una prueba t de Student. Así que…